Generator teks-ke-gambar Google Imagen menghasilkan gambar dengan 'tingkat fotorealisme yang belum pernah terjadi sebelumnya'
![]() 3 menit Baca
3 menit Baca
![]() Ditampilkan di
Ditampilkan di
Bagikan artikel ini

Sempurnakan panduan ini
Baca halaman pengungkapan kami untuk mengetahui bagaimana Anda dapat membantu MSPoweruser mempertahankan tim editorial Baca lebih lanjut
Google meluncurkan kreasi baru yang disebut “Gambar,” generator teks-ke-gambar melalui deskripsi yang akan diberikan seseorang. Perusahaan mengklaim bahwa itu melampaui kinerja DALL-E 2, generator gambar AI lainnya. Itu menyajikan beberapa sampel, yang tidak dapat disangkal menunjukkan detail yang sangat indah, tetapi Imagen saat ini tidak tersedia untuk umum.
Model difusi teks-ke-gambar yang baru digambarkan memiliki “tingkat fotorealisme yang belum pernah terjadi sebelumnya dan tingkat pemahaman bahasa yang mendalam.” Ini memahami teks melalui model bahasa transformator besar dan dikatakan mengandalkan model difusi untuk melakukan pembuatan gambar dengan ketelitian tinggi.

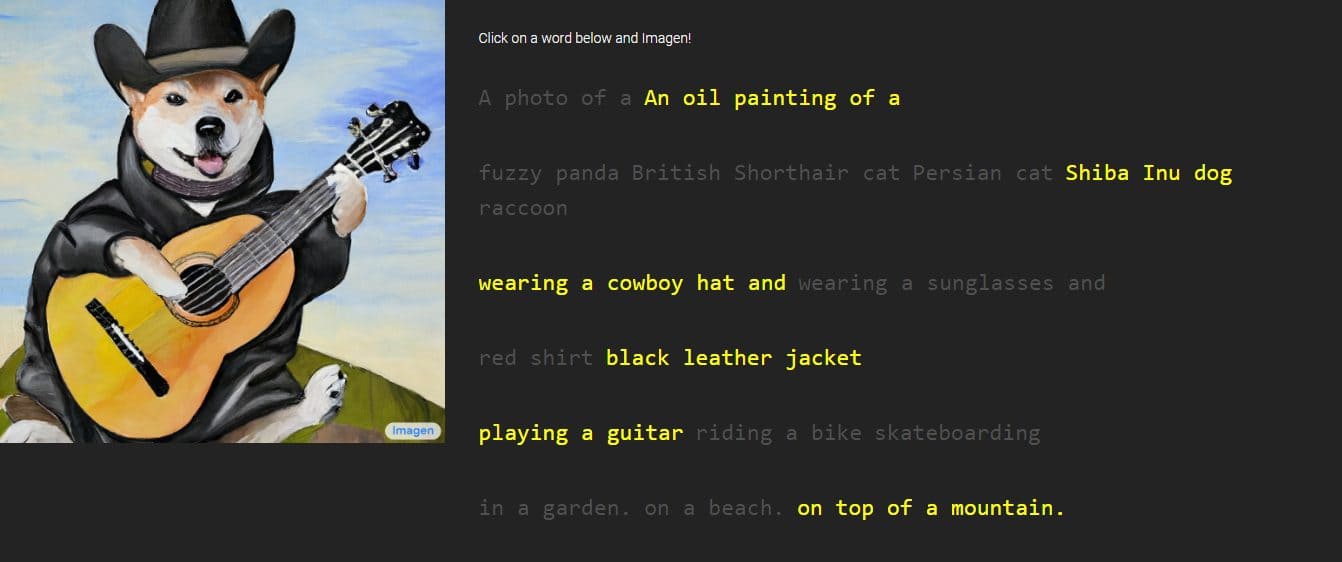
Google menyediakan gambar dan contoh karya Imagen, dengan gaya yang bervariasi mulai dari gambar hingga lukisan cat minyak dan CGI. Mereka disertai dengan kata-kata dan frase yang digunakan untuk menghasilkan mereka. Misalnya, satu sampel berbunyi, "buah naga mengenakan sabuk karate di salju," sementara yang lain memiliki deskripsi "kaktus kecil mengenakan topi jerami dan kacamata hitam neon di gurun Sahara."
Gambar yang dihasilkan terlihat sangat nyata seolah-olah dibuat oleh orang yang sebenarnya. Namun, Google mengatakan bahwa itu dilakukan melalui teknologi difusi dengan memanfaatkan gambar noise murni dan menyempurnakannya dengan cara terbaik. Dengan memahami deskripsi teks yang diberikan, Imagen akan menghasilkan gambar 64 x 64 piksel, melakukan dua peningkatan, dan mengubah gambar menjadi potongan 1024 x 1024 piksel yang lebih besar.
Google Research, Brain Team mengatakan bahwa Imagen unggul dalam COCO (set data deteksi objek, segmentasi, dan teks skala besar) meskipun tidak dilatih tentangnya. Tim tersebut melaporkan bahwa mereka menerima skor FID mutakhir baru sebesar 7.27.
Google juga membandingkan kinerja Imagen dengan model teks-ke-gambar lainnya dengan menilai mereka menggunakan "DrawBench." Ini berfungsi sebagai patokan untuk model teks-ke-gambar di mana Google menguji Imagen dengan metode lain seperti VQ-GAN+CLIP, Model Difusi Laten, dan DALL-E 2. Setelah pengujian untuk komposisi, kardinalitas, hubungan spasial, bentuk panjangnya teks, kata-kata langka, dan permintaan yang menantang, tim mengatakan bahwa "penilai manusia sangat memilih Imagen daripada metode lain, baik dalam penyelarasan gambar-teks dan kesetiaan gambar."
Terlepas dari laporan yang mengesankan dari tim peneliti ini, pengujian Imagen sendiri tidak akan mungkin dilakukan karena tidak dapat diakses oleh publik. Google memiliki alasan untuk itu, seperti tantangan etika, potensi risiko penyalahgunaan, bias sosial, keterbatasan model bahasa yang besar, dan risiko stereotip dan representasi berbahaya yang dikodekan. Tim menyimpulkan bahwa dengan semua tantangan ini, Imagen masih belum sempurna dalam hal menghasilkan gambar yang berhubungan dengan orang.
“Imagen menunjukkan batasan serius saat menghasilkan gambar yang menggambarkan orang,” tim menjelaskan dalam posting blog. “Evaluasi manusia kami menemukan bahwa Imagen memperoleh tingkat preferensi yang jauh lebih tinggi ketika dievaluasi pada gambar yang tidak menggambarkan orang, menunjukkan penurunan dalam kesetiaan gambar. Penilaian awal juga menunjukkan bahwa Imagen mengkodekan beberapa bias dan stereotip sosial, termasuk bias keseluruhan untuk menghasilkan gambar orang dengan warna kulit lebih terang dan kecenderungan gambar yang menggambarkan profesi yang berbeda untuk disejajarkan dengan stereotip gender Barat. Akhirnya, bahkan ketika kami memfokuskan generasi jauh dari orang, analisis awal kami menunjukkan Imagen mengkodekan berbagai bias sosial dan budaya saat menghasilkan gambar aktivitas, peristiwa, dan objek. Kami bertujuan untuk membuat kemajuan pada beberapa tantangan dan keterbatasan terbuka ini dalam pekerjaan di masa depan.”