A Microsoft bejelentette két adattudományi segédprogram nyilvános elérhetőségét
![]() 1 perc olvas
1 perc olvas
![]() Publikálva
Publikálva
Ossza meg ezt a cikket

Javítsa ezt az útmutatót
Olvassa el közzétételi oldalunkat, hogy megtudja, hogyan segítheti az MSPowerusert a szerkesztői csapat fenntartásában Tovább
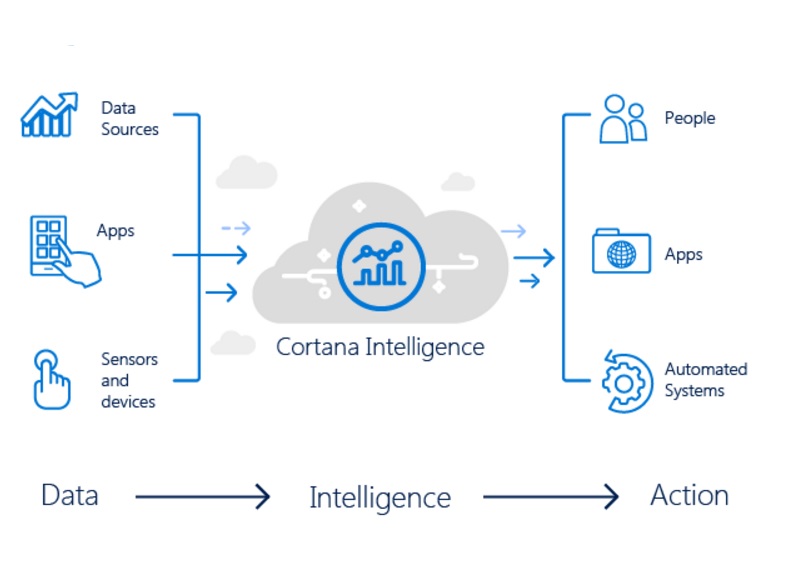
Az adattudósok jelentős időt töltenek kódírással, és az idő nagy részében választ keresnek az alábbi kérdésekre.
- Hogyan néznek ki az adatok? Mi a séma?
- Milyen minőségűek az adatok? Milyen súlyosságúak a hiányzó adatok?
- Hogyan oszlanak meg az egyes változók? Változótranszformációt kell végeznem?
- Mennyire relevánsak az adatok a gépi tanulási feladat szempontjából? Mennyire nehéz maga a gépi tanulási feladat?
- Mely változók a leginkább relevánsak a gépi tanulási cél szempontjából?
- Van-e konkrét klaszterezési minta az adatokban?
- Hogyan teljesítenek az adatokon lévő ML-modellek? Mely változók szignifikánsak a modellekben?
A kód nagy része általánosítható adattudományi segédprogramokká, amelyek újrafelhasználhatók a projektekben, segítve az adatkutatókat, hogy irányított módban dolgozzanak a projektben meghatározott feladatokon, biztosítva a mögöttes feladatok következetességét és teljességét. Az adattudósok segítésére a Microsoft két adattudományi segédprogramot ad ki,
- Interaktív adatfeltárás, -elemzés és -jelentés (IDEAR), ill
- Automatizált modellezés és jelentéskészítés (AMAR).
Ez a két, CRAN-R-ben futó segédprogram a címről érhető el ezen a GitHub webhelyen.
Olvasson többet ezekről a segédprogramokról itt.







