Le petit modèle NeMo de Mistral défie le dernier mini GPT-4o d'OpenAI
OpenAI a lancé le GPT-4o mini il n'y a pas si longtemps
![]() 2 minute. lis
2 minute. lis
![]() Publié le
Publié le
Partagez cet article

Améliorer ce guide
Lisez notre page de divulgation pour savoir comment vous pouvez aider MSPoweruser à soutenir l'équipe éditoriale En savoir plus.
Notes clés
- Mistral AI a publié NeMo, un modèle 12B avec le soutien de Nvidia, rivalisant avec le GPT-4o mini d'OpenAI.
- NeMo prend en charge 128 68.0 jetons et obtient un score de 4 % sur MMLU, en dessous des 82 % de GPT-XNUMXo mini.
- Mistral, financé à hauteur de 645 millions de dollars, s'est associé à Microsoft pour proposer des modèles sur Azure.

Mistral AI vient d'annoncer son dernier modèle plus petit, Némo, avec le fort soutien de Nvidia. Il est intéressant de noter que l'annonce a été faite alors qu'OpenAI annonçait son modèle léger et économique, le GPT-4o mini, qui obtient de meilleurs chiffres de référence que Gemini Flash et Claude Haiku.
Ce modèle 12B « de pointe » prend en charge une longueur de contexte allant jusqu'à 128 2.0 jetons et est conçu pour des performances élevées en matière de raisonnement, de connaissance du monde et de précision de codage, et est actuellement disponible sous la licence Apache XNUMX. Les deux base et adapté aux instructions les versions sont accessibles sur HuggingFace et d’autres plateformes.
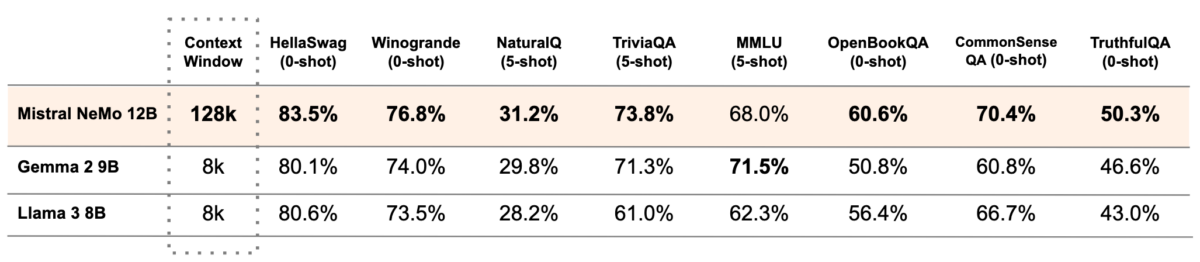
Le NeMo de Mistral enregistre également quelques performances de référence impressionnantes. L'analyse comparative MMLU, qui mesure les connaissances globales d'un modèle et ses capacités de résolution de problèmes, voit NeMo obtenir un score de 68.0 %. C'est assez proche du Gemma 2 de Google, mais pas assez pour se rapprocher de celui d'OpenAI. GPT-4o mini qui a un 82% sur MMLU.
Voici à quoi ressemble ce dernier :
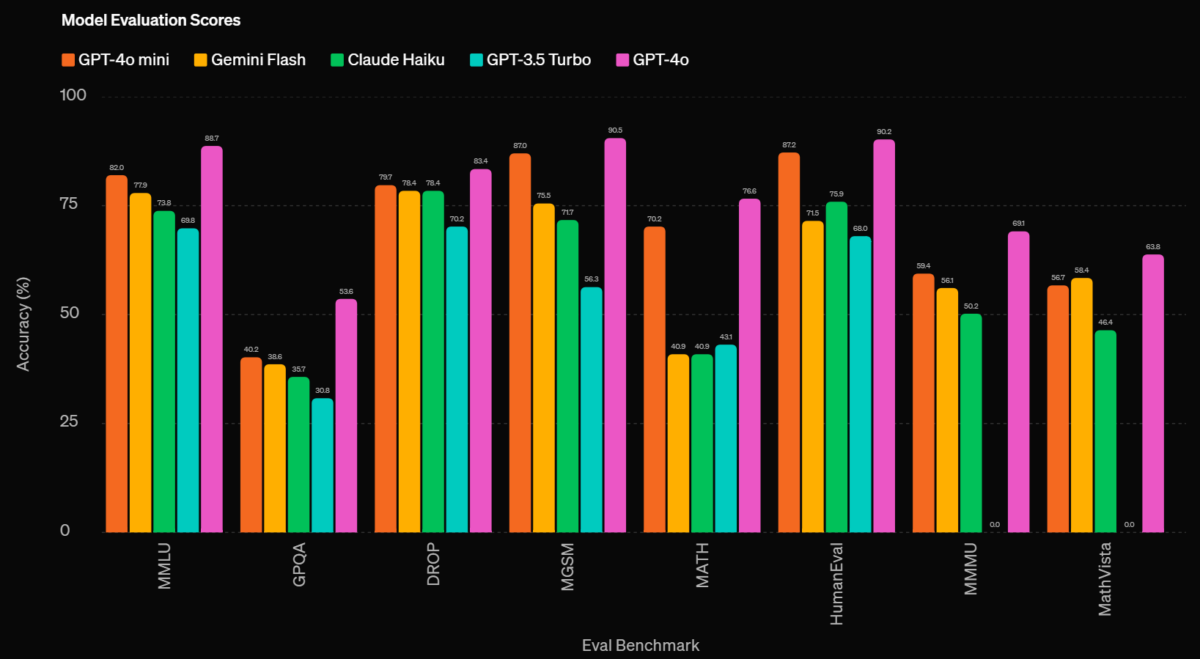
Le modèle polyvalent et multilingue enregistre également de solides capacités dans diverses langues et est formé pour des appels de fonctions efficaces. Il utilise le tokenizer avancé Tekken, qui compresse le texte et le code plus efficacement que les modèles précédents, en particulier dans des langues spécifiques.
Mistral est arrivé il n'y a pas si longtemps, à peine plus d'un an d'anciens employés de Meta et Google DeepMind. L’entreprise, qui a bénéficié d’un financement d’environ 645 millions de dollars en juin 2024, a déjà fait des vagues dans la course à l’IA.
Plus tôt cette année, Microsoft et Mistral AI ont également annoncé un partenariat qui voit les grands modèles de langage avancés (LLM) de Mistral disponibles en premier sur la plate-forme cloud Azure de Microsoft. La société a également rejoint OpenAI pour proposer des modèles commerciaux sur Azure.




Forum des utilisateurs
Messages 0