Découvrez Microsoft DeepSpeed, une nouvelle bibliothèque d'apprentissage en profondeur capable de former des modèles massifs de 100 milliards de paramètres
![]() 2 minute. lis
2 minute. lis
![]() Mis à jour le
Mis à jour le
Partagez cet article

Améliorer ce guide
Lisez notre page de divulgation pour savoir comment vous pouvez aider MSPoweruser à soutenir l'équipe éditoriale En savoir plus
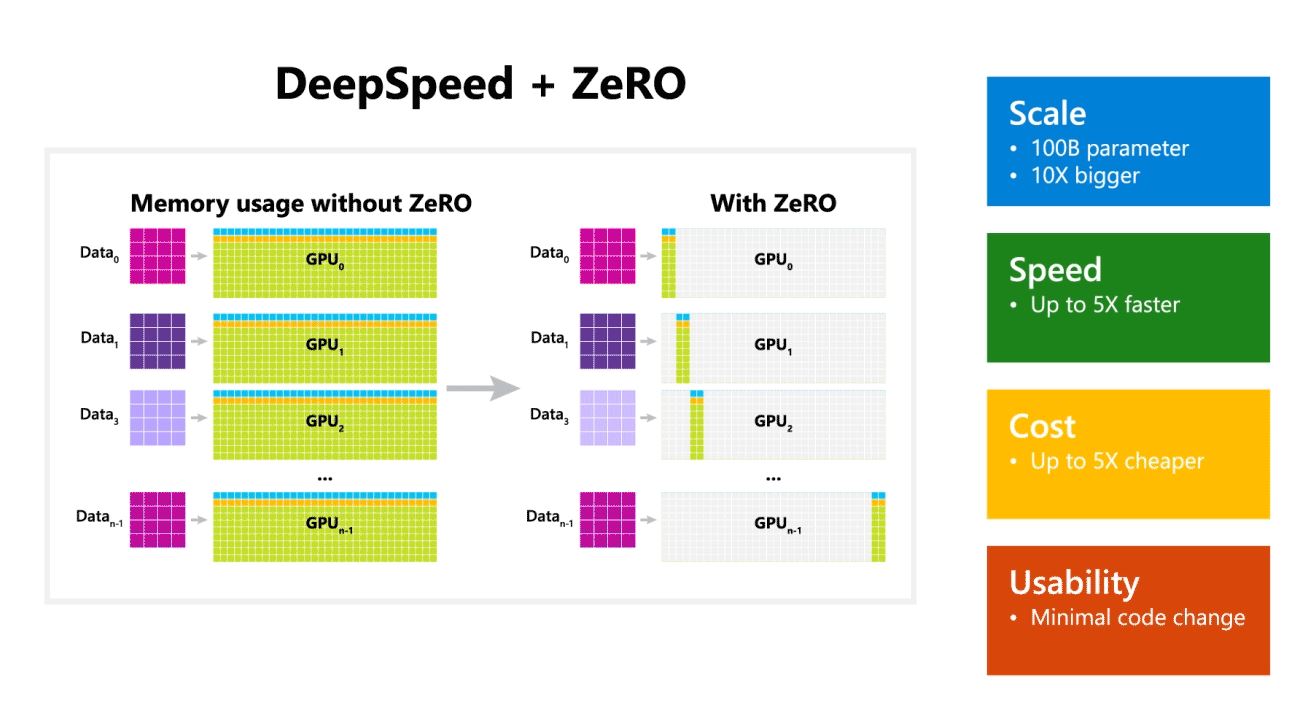
Microsoft Research a annoncé aujourd'hui DeepSpeed, une nouvelle bibliothèque d'optimisation d'apprentissage en profondeur capable de former des modèles massifs de 100 milliards de paramètres. En IA, vous devez disposer de modèles de langage naturel plus grands pour une meilleure précision. Mais la formation de modèles de langage naturel plus grands prend du temps et les coûts qui y sont associés sont très élevés. Microsoft affirme que la nouvelle bibliothèque d'apprentissage en profondeur DeepSpeed améliore la vitesse, le coût, l'échelle et la convivialité.
Microsoft a également mentionné que DeepSpeed permet des modèles de langage avec jusqu'à 100 milliards de modèles de paramètres et qu'il inclut ZeRO (Zero Redundancy Optimizer), un optimiseur parallélisé qui réduit les ressources nécessaires au parallélisme des modèles et des données tout en augmentant le nombre de paramètres pouvant être formés. . En utilisant DeepSpeed et ZeRO, les chercheurs de Microsoft ont développé la nouvelle génération Turing Natural Language (Turing-NLG), le plus grand modèle de langage avec 17 milliards de paramètres.
Points forts de DeepSpeed :
- Escaliers intérieurs: Les grands modèles à la pointe de la technologie tels que OpenAI GPT-2, NVIDIA Megatron-LM et Google T5 ont respectivement des tailles de 1.5 milliard, 8.3 milliards et 11 milliards de paramètres. La première étape de ZeRO dans DeepSpeed fournit une prise en charge du système pour exécuter des modèles jusqu'à 100 milliards de paramètres, soit 10 fois plus.
- Vitesse: Nous observons un débit jusqu'à cinq fois plus élevé par rapport à l'état de l'art sur divers matériels. Sur les clusters GPU NVIDIA avec interconnexion à faible bande passante (sans NVIDIA NVLink ou Infiniband), nous obtenons une amélioration du débit de 3.75 fois par rapport à l'utilisation de Megatron-LM seul pour un modèle GPT-2 standard avec 1.5 milliard de paramètres. Sur les clusters NVIDIA DGX-2 avec interconnexion haut débit, pour des modèles de 20 à 80 milliards de paramètres, nous sommes trois à cinq fois plus rapides.
- Prix: Un débit amélioré peut se traduire par une réduction significative des coûts de formation. Par exemple, pour former un modèle avec 20 milliards de paramètres, DeepSpeed nécessite trois fois moins de ressources.
- Convivialité: Seules quelques lignes de modifications de code sont nécessaires pour permettre à un modèle PyTorch d'utiliser DeepSpeed et ZeRO. Par rapport aux bibliothèques de parallélisme de modèles actuelles, DeepSpeed ne nécessite pas de refonte de code ou de refactorisation de modèle.
Microsoft est open source à la fois DeepSpeed et ZeRO, vous pouvez le vérifier ici sur GitHub.
La source: Microsoft