Microsoft todistaa, että GPT-4 voi voittaa Google Gemini Ultran käyttämällä uusia kehotustekniikoita
![]() 2 min. lukea
2 min. lukea
![]() Julkaistu
Julkaistu
Jaa tämä artikkeli

Paranna tätä ohjetta
Lue ilmoitussivumme saadaksesi selville, kuinka voit auttaa MSPoweruseria ylläpitämään toimitustiimiä Lue lisää
Google ilmoitti viime viikolla Kaksoset, sen tehokkain ja yleisin malli tähän mennessä. Google Gemini -malli tarjoaa huippuluokan suorituskyvyn monissa johtavissa vertailuissa. Google korosti, että tehokkain Gemini Ultra -mallin suorituskyky ylittää OpenAI GPT-4:n tulokset 30:ssä laajalti käytetystä 32 akateemisesta vertailuarvosta, joita käytetään suurten kielimallien (LLM) tutkimuksessa ja kehityksessä.
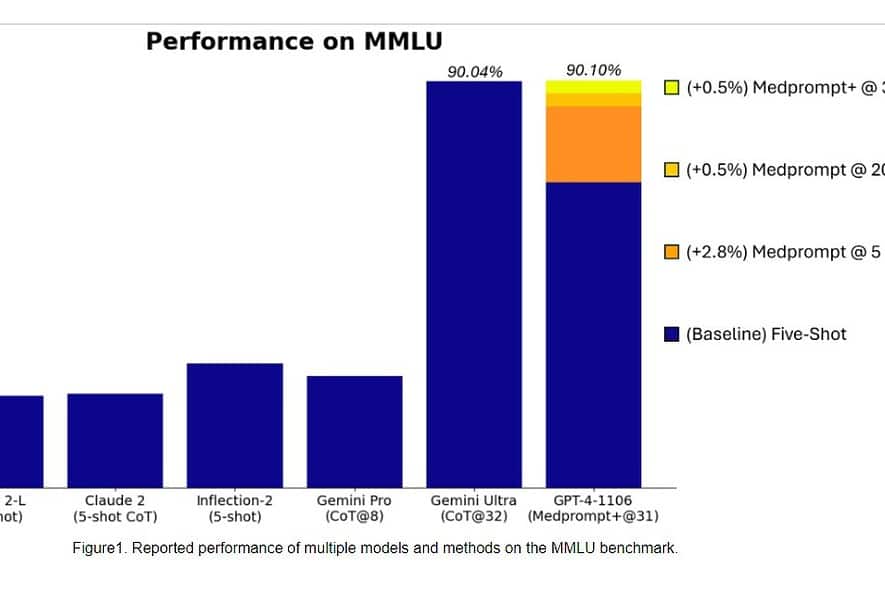
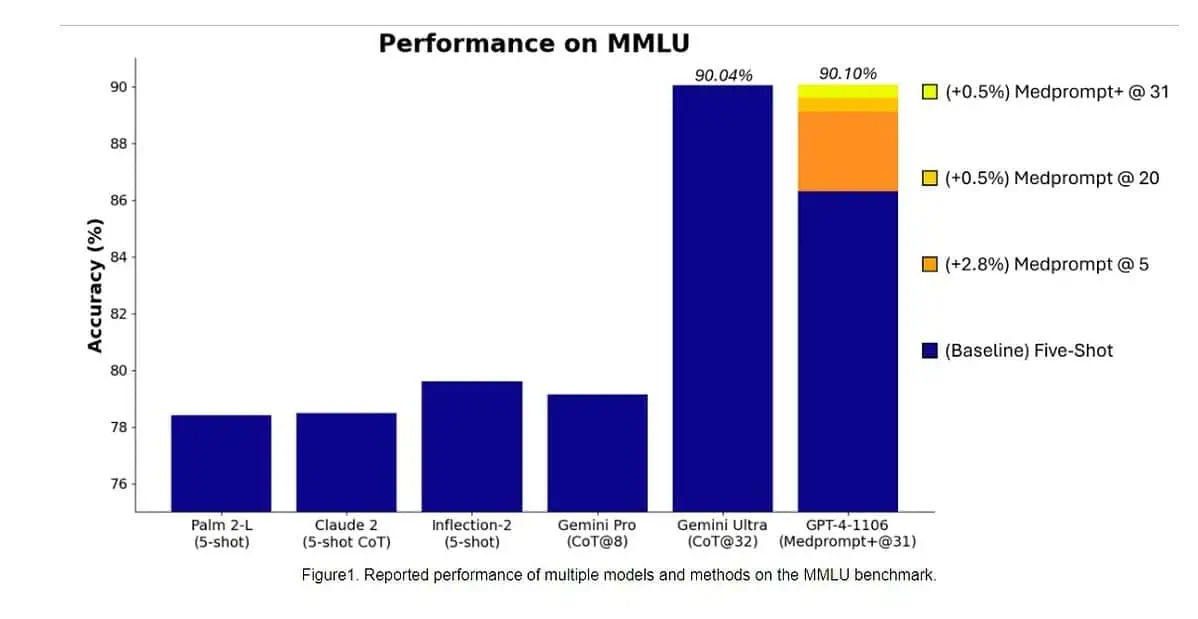
Tarkemmin sanottuna Gemini Ultrasta tuli ensimmäinen malli, joka päihitti ihmisasiantuntijat MMLU:ssa (massive multitask language ymmärrys) 90 % pistemäärällä, joka käyttää 57 aiheen yhdistelmää, kuten matematiikkaa, fysiikkaa, historiaa, lakia, lääketiedettä ja etiikkaa molempien maailmantiedon testaamiseen. ja ongelmanratkaisukykyjä.
Eilen Microsoftin tutkimusryhmä paljasti että OpenAI:n GPT-4-malli voi voittaa Google Gemini Ultran, kun käytetään uusia kehotustekniikoita. Viime kuussa Microsoft Research paljasti Medprompt, yhdistelmä useista kehotusstrategioista, joka parantaa huomattavasti GPT-4:n suorituskykyä ja saavuttaa huippuluokan tuloksia MultiMedQA-sarjassa. Microsoft on nyt soveltanut Medpromptissa käytettyjä kehotustekniikoita myös yleisiin toimialueisiin. Microsoftin mukaan OpenAI:n GPT-4-malli, kun sitä käytetään Medpromptin muokatun version kanssa, saavuttaa kaikkien aikojen korkeimmat pisteet koko MMLU:ssa. Kyllä, OpenAI GPT-4 voi voittaa tulevan Gemini Ultra -mallin vain käyttämällä kehotustekniikoita. Tämä osoittaa, että emme ole vielä saavuttaneet jo julkaistujen mallien, kuten GPT-4:n, täyttä potentiaalia.
Katso alla olevaa vertailua GPT-4:n (parannetut kehotteet) ja Gemini Ultra -mallien välillä.
| benchmark | GPT-4-kehote | GPT-4 tulokset | Gemini Ultra -tulokset |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Nollalaukaus | 95.27% | 94.4% |
| MATEMATIIKKA | Nollalaukaus | 68.42% | 53.2% |
| HumanEval | Nollalaukaus | 87.8% | 74.4% |
| BIG-Bench-Hard | Muutama laukaus + CoT* | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10 laukausta** | 95.3% | 87.8% |
Ensin Microsoft sovelsi alkuperäistä Medpromptia GPT-4:ään saavuttaakseen 89.1 prosentin pistemäärän MMLU:ssa. Myöhemmin Microsoft lisäsi Medpromptin yhdistelmäpuhelujen määrää viidestä 20:een, mikä johti 89.56 prosentin nousuun. Microsoft laajensi myöhemmin Medpromptin Medprompt+:aan lisäämällä yksinkertaisemman kehotusmenetelmän ja laatimalla käytännön lopullisen vastauksen saamiseksi integroimalla tulosteet sekä Medprompt-perusstrategiasta että yksinkertaisista kehotteista. Tämä johti GPT-4:n saavuttamaan ennätyspisteet 90.10 %. Microsoftin tutkimustiimi mainitsi, että Google Gemini -tiimi käytti myös samanlaista kehotustekniikkaa saavuttaakseen ennätyspisteet MMLU:ssa.
Voit oppia lisää kehotustekniikoista, joita Microsoft käytti voittaakseen Gemini Ultran tätä.