مولد متن به تصویر گوگل، Imagen، تصاویری با درجه بیسابقه فوتورئالیسم تولید میکند.
![]() 3 دقیقه خواندن
3 دقیقه خواندن
![]() منتشر شده در
منتشر شده در
این مقاله را به اشتراک بگذارید

این راهنما را بهبود بخشید
صفحه افشای ما را بخوانید تا بدانید چگونه می توانید به MSPoweruser کمک کنید تا تیم تحریریه را حفظ کند ادامه مطلب
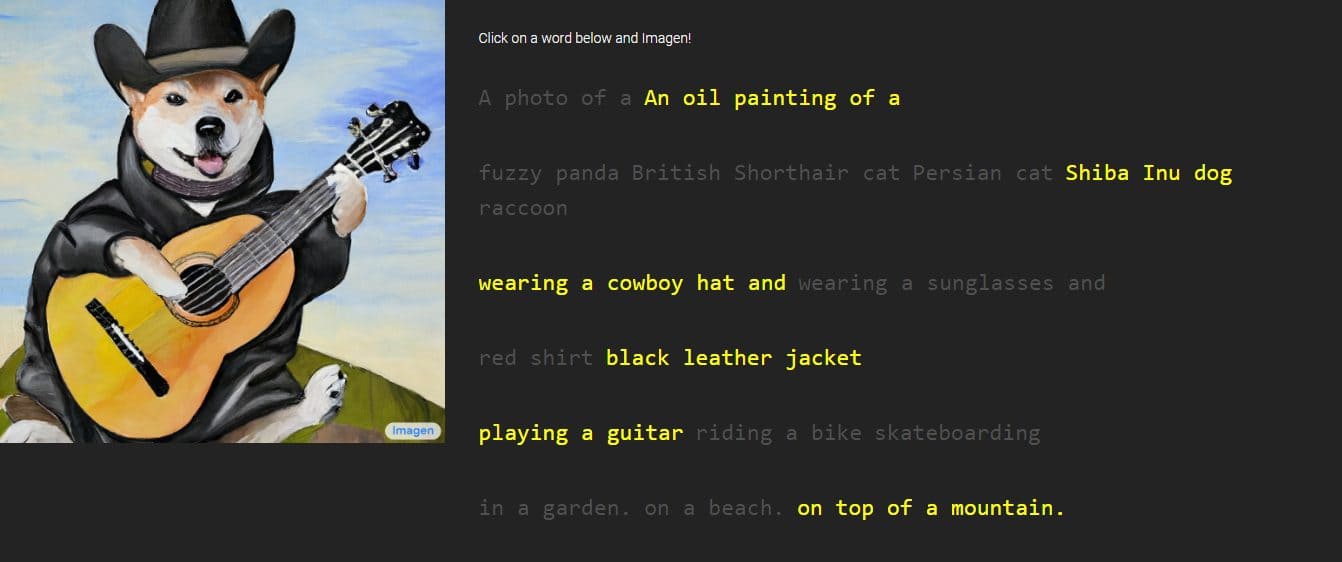
گوگل رونمایی از یک خلاقیت جدید به نام "تصویر، یک تولید کننده متن به تصویر از طریق توضیحاتی که شخص ارائه می دهد. این شرکت ادعا می کند که از عملکرد DALL-E 2، یکی دیگر از تولیدکنندگان تصویر هوش مصنوعی، پیشی گرفته است. نمونههایی را ارائه کرد که غیرقابل انکار جزئیات بسیار خوبی را نشان میدهد، اما Imagen در حال حاضر در دسترس عموم نیست.
مدل جدید انتشار متن به تصویر به عنوان "درجه بی سابقه ای از فوتورئالیسم و سطح عمیقی از درک زبان" توصیف شده است. متن را از طریق مدلهای زبان ترانسفورماتور بزرگ درک میکند و گفته میشود که برای تولید تصویر با وفاداری بالا به مدلهای انتشار متکی است.

گوگل تصاویر و نمونه هایی از کارهای ایمیجن را با سبک های مختلف از طراحی گرفته تا نقاشی رنگ روغن و CGI ارائه کرد. آنها با کلمات و عبارات مورد استفاده برای تولید آنها همراه هستند. به عنوان مثال، یکی از نمونه ها می گوید: "یک میوه اژدها با کمربند کاراته در برف"، در حالی که دیگری توصیف "کاکتوس کوچکی با کلاه حصیری و عینک آفتابی نئون در صحرای صحرا" است.
تصاویر تولید شده به طور باورنکردنی واقعی به نظر می رسند که گویی توسط یک شخص واقعی خلق شده اند. با این حال، گوگل می گوید که این کار از طریق فناوری های انتشار با استفاده از یک تصویر نویز خالص و اصلاح آن به بهترین شکل ممکن انجام می شود. با درک توضیحات متن ارائه شده، Imagen یک تصویر 64 x 64 پیکسل ایجاد می کند، دو ارتقاء را انجام می دهد و تصویر را به یک قطعه بزرگتر 1024 x 1024 پیکسل تبدیل می کند.
تحقیقات گوگل، تیم مغز میگوید که Imagen در این زمینه عالی بود COCO (یک مجموعه داده شناسایی، تقسیمبندی و زیرنویس شی در مقیاس بزرگ) علیرغم عدم آموزش روی آن. این تیم گزارش داد که امتیاز جدید FID 7.27 را دریافت کرده است.
گوگل همچنین عملکرد Imagen را با سایر مدلهای تبدیل متن به تصویر با استفاده از «DrawBench» ارزیابی کرد. این به عنوان معیاری برای مدلهای متن به تصویر عمل میکند که Google Imagen را با روشهای دیگری مانند VQ-GAN+CLIP، مدلهای انتشار پنهان، و DALL-E 2 آزمایش کرد. متن، کلمات کمیاب، و درخواستهای چالش برانگیز، این تیم گفت که «ارزشدهندههای انسانی به شدت Imagen را به روشهای دیگر ترجیح میدهند، هم در تراز تصویر-متن و هم در وفاداری تصویر».
علیرغم این گزارشهای چشمگیر تیم تحقیقاتی، آزمایش Imagen توسط خودتان امکانپذیر نخواهد بود، زیرا برای عموم قابل دسترسی نیست. Google برای آن دلایلی دارد، مانند چالشهای اخلاقی، خطرات احتمالی سوءاستفاده، سوگیریهای اجتماعی، محدودیتهای مدلهای زبانی بزرگ، و خطر کلیشهها و بازنماییهای مضر رمزگذاریشده. تیم به طور خلاصه بیان می کند که با وجود همه این چالش ها، Imagen هنوز در تولید تصاویر مربوط به افراد بی نقص نیست.
این تیم در یک پست وبلاگ توضیح می دهد: "Imagen در هنگام تولید تصاویری که افراد را به تصویر می کشد محدودیت های جدی نشان می دهد." ارزیابیهای انسانی ما نشان میدهد که Imagen در هنگام ارزیابی روی تصاویری که افراد را به تصویر نمیکشند، به میزان قابلتوجهی اولویت بیشتری به دست میآورد که نشاندهنده کاهش وفاداری تصویر است. ارزیابی اولیه همچنین نشان میدهد که Imagen چندین سوگیری اجتماعی و کلیشهای را رمزگذاری میکند، از جمله یک سوگیری کلی نسبت به ایجاد تصاویری از افراد با رنگ پوست روشنتر و تمایل به تصاویری که حرفههای مختلف را به تصویر میکشند تا با کلیشههای جنسیتی غربی همسو شوند. در نهایت، حتی زمانی که ما نسلها را دور از مردم متمرکز میکنیم، تحلیل اولیه ما نشان میدهد که Imagen هنگام تولید تصاویری از فعالیتها، رویدادها و اشیا، طیفی از سوگیریهای اجتماعی و فرهنگی را رمزگذاری میکند. هدف ما این است که در چندین مورد از این چالش ها و محدودیت های باز در کارهای آینده پیشرفت کنیم."