Imagen, el generador de texto a imagen de Google, produce imágenes con un "grado de fotorrealismo sin precedentes"
![]() 3 minuto. leer
3 minuto. leer
![]() Publicado el
Publicado el
Compartir este artículo

Mejorar esta guía
Lea nuestra página de divulgación para descubrir cómo puede ayudar a MSPoweruser a sostener el equipo editorial. Leer más
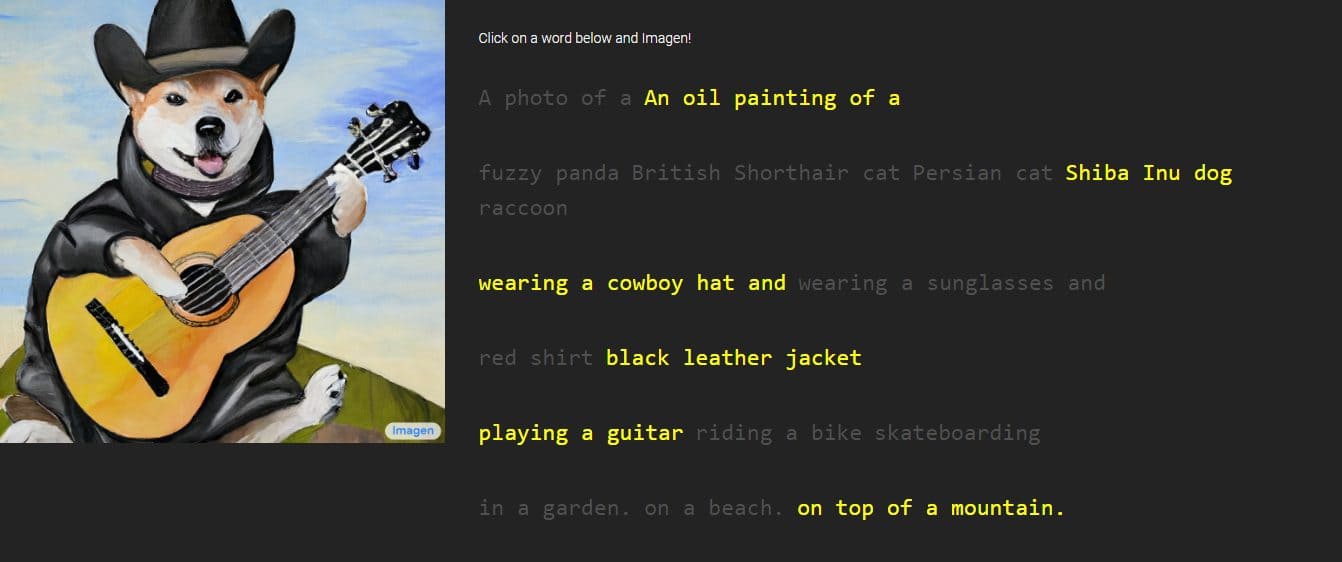
Google dio a conocer una nueva creación llamada “Imagen”, un generador de texto a imagen a través de descripciones que proporcionará una persona. La empresa afirma que supera el rendimiento de DALL-E 2, otro generador de imágenes de IA. Presentó algunas muestras, que sin duda muestran detalles exquisitos, pero Imagen no está disponible para el público por el momento.
Se describe que el nuevo modelo de difusión de texto a imagen tiene "un grado sin precedentes de fotorrealismo y un profundo nivel de comprensión del lenguaje". Entiende el texto a través de grandes modelos de lenguaje transformador y se dice que se basa en modelos de difusión para realizar la generación de imágenes de alta fidelidad.

Google proporcionó imágenes y muestras del trabajo de Imagen, con estilos que varían desde dibujos hasta pinturas al óleo y CGI. Van acompañados de las palabras y frases utilizadas para generarlos. Por ejemplo, una muestra dice "una fruta del dragón con un cinturón de kárate en la nieve", mientras que la otra tiene la descripción "un pequeño cactus con un sombrero de paja y gafas de sol de neón en el desierto del Sahara".
Las imágenes generadas se ven increíblemente reales como si fueran creadas por una persona real. Sin embargo, Google dice que se hace a través de tecnologías de difusión utilizando una imagen de ruido puro y refinándola de la mejor manera posible. Al comprender la descripción del texto proporcionado, Imagen generará una imagen de 64 x 64 píxeles, realizará dos mejoras y convertirá la imagen en una pieza más grande de 1024 x 1024 píxeles.
Google Research, Brain Team dice que Imagen sobresalió en COCO (un conjunto de datos de subtítulos, segmentación y detección de objetos a gran escala) a pesar de no estar entrenado en él. El equipo informó que recibió una nueva puntuación FID de última generación de 7.27.
Google también comparó el rendimiento de Imagen con otros modelos de texto a imagen evaluándolos mediante "DrawBench". Sirve como punto de referencia para los modelos de texto a imagen donde Google probó Imagen con otros métodos como VQ-GAN+CLIP, modelos de difusión latente y DALL-E 2. Después de probar su composicionalidad, cardinalidad, relaciones espaciales, formato largo texto, palabras raras e indicaciones desafiantes, el equipo dijo que "los evaluadores humanos prefieren fuertemente Imagen sobre otros métodos, tanto en la alineación de imagen y texto como en la fidelidad de la imagen".
A pesar de estos impresionantes informes del equipo de investigación, no será posible probar Imagen usted mismo, ya que no es accesible al público. Google tiene razones para ello, como desafíos éticos, riesgos potenciales de uso indebido, sesgos sociales, limitaciones de modelos de lenguaje extenso y riesgo de representaciones y estereotipos dañinos codificados. El equipo resume que con todos estos desafíos, Imagen aún no es perfecta a la hora de generar imágenes relacionadas con las personas.
“Imagen exhibe serias limitaciones al generar imágenes que representan personas”, explica el equipo en una publicación de blog. “Nuestras evaluaciones humanas encontraron que Imagen obtiene tasas de preferencia significativamente más altas cuando se evalúa en imágenes que no retratan a personas, lo que indica una degradación en la fidelidad de la imagen. La evaluación preliminar también sugiere que Imagen codifica varios sesgos y estereotipos sociales, incluido un sesgo general hacia la generación de imágenes de personas con tonos de piel más claros y una tendencia a que las imágenes que representan diferentes profesiones se alineen con los estereotipos de género occidentales. Finalmente, incluso cuando enfocamos a las generaciones lejos de las personas, nuestro análisis preliminar indica que Imagen codifica una variedad de sesgos sociales y culturales al generar imágenes de actividades, eventos y objetos. Nuestro objetivo es avanzar en varios de estos desafíos abiertos y limitaciones en el trabajo futuro”.