Γνωρίστε το Microsoft DeepSpeed, μια νέα βιβλιοθήκη βαθιάς μάθησης που μπορεί να εκπαιδεύσει τεράστια μοντέλα 100 δισεκατομμυρίων παραμέτρων
![]() 2 λεπτό. ανάγνωση
2 λεπτό. ανάγνωση
![]() Ενημερώθηκε στις
Ενημερώθηκε στις
Μοιραστείτε αυτό το άρθρο

Βελτιώστε αυτόν τον οδηγό
Διαβάστε τη σελίδα αποκάλυψης για να μάθετε πώς μπορείτε να βοηθήσετε το MSPoweruser να διατηρήσει τη συντακτική ομάδα Διάβασε περισσότερα
Η Microsoft Research ανακοίνωσε σήμερα το DeepSpeed, μια νέα βιβλιοθήκη βελτιστοποίησης βαθιάς μάθησης που μπορεί να εκπαιδεύσει τεράστια μοντέλα 100 δισεκατομμυρίων παραμέτρων. Στο AI, πρέπει να έχετε μεγαλύτερα μοντέλα φυσικής γλώσσας για καλύτερη ακρίβεια. Αλλά η εκπαίδευση μεγαλύτερων μοντέλων φυσικής γλώσσας είναι χρονοβόρα και το κόστος που συνδέεται με αυτό είναι πολύ υψηλό. Η Microsoft ισχυρίζεται ότι η νέα βιβλιοθήκη βαθιάς εκμάθησης DeepSpeed βελτιώνει την ταχύτητα, το κόστος, την κλίμακα και τη χρηστικότητα.
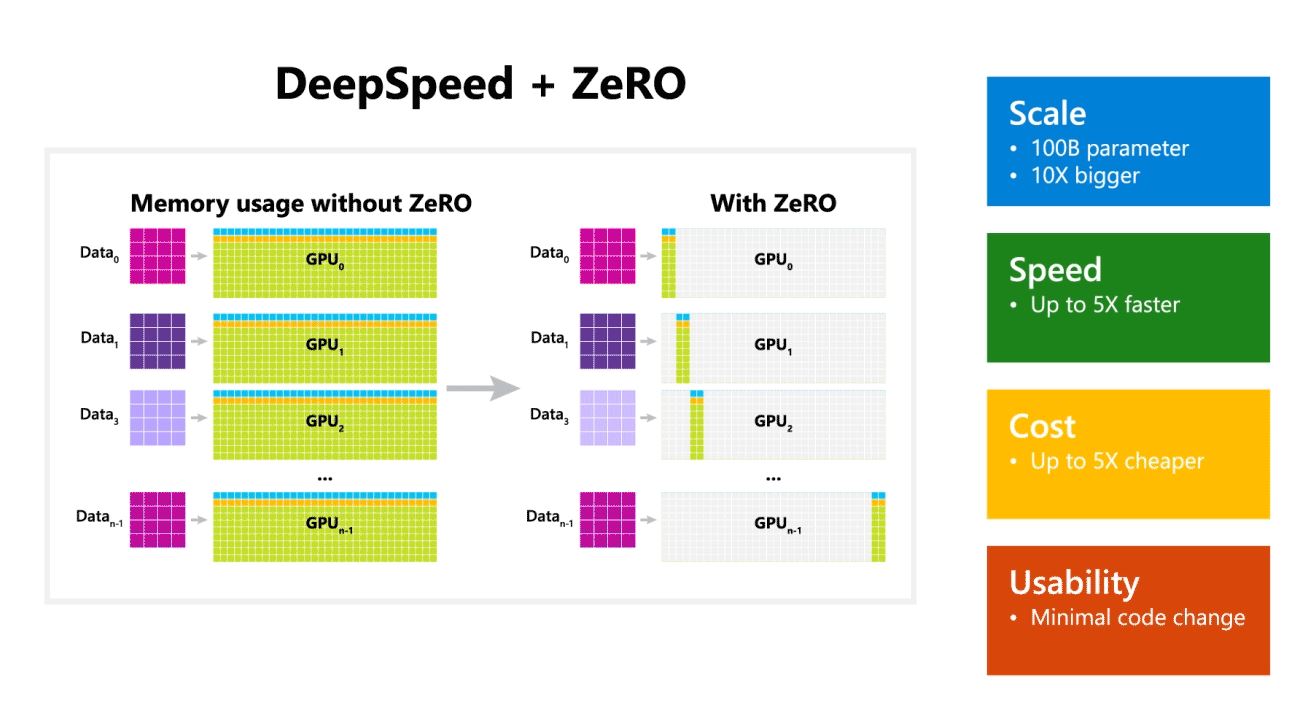
Η Microsoft ανέφερε επίσης ότι το DeepSpeed ενεργοποιεί μοντέλα γλώσσας με μοντέλα έως και 100 δισεκατομμυρίων παραμέτρων και περιλαμβάνει το ZeRO (Zero Redundancy Optimizer), έναν παραλληλισμένο βελτιστοποιητή που μειώνει τους πόρους που απαιτούνται για τον παραλληλισμό μοντέλων και δεδομένων, ενώ αυξάνει τον αριθμό των παραμέτρων που μπορούν να εκπαιδευτούν . Χρησιμοποιώντας το DeepSpeed και το ZeRO, οι Ερευνητές της Microsoft ανέπτυξαν τη νέα Turing Natural Language Generation (Turing-NLG), το μεγαλύτερο μοντέλο γλώσσας με 17 δισεκατομμύρια παραμέτρους.
Τα κυριότερα σημεία του DeepSpeed:
- Κλίμακα: Τα υπερσύγχρονα μεγάλα μοντέλα όπως το OpenAI GPT-2, το NVIDIA Megatron-LM και το Google T5 έχουν μεγέθη 1.5 δισεκατομμυρίων, 8.3 δισεκατομμυρίων και 11 δισεκατομμυρίων παραμέτρων αντίστοιχα. Το στάδιο ZeRO ένα στο DeepSpeed παρέχει υποστήριξη συστήματος για την εκτέλεση μοντέλων έως και 100 δισεκατομμυρίων παραμέτρων, 10 φορές μεγαλύτερες.
- Ταχύτητα: Παρατηρούμε έως και πέντε φορές υψηλότερη απόδοση σε σχέση με την τελευταία λέξη της τεχνολογίας σε διάφορα υλικά. Σε συμπλέγματα GPU NVIDIA με διασύνδεση χαμηλού εύρους ζώνης (χωρίς NVIDIA NVLink ή Infiniband), επιτυγχάνουμε βελτίωση απόδοσης 3.75x σε σχέση με τη χρήση μόνο του Megatron-LM για ένα τυπικό μοντέλο GPT-2 με 1.5 δισεκατομμύρια παραμέτρους. Σε συμπλέγματα NVIDIA DGX-2 με διασύνδεση υψηλού εύρους ζώνης, για μοντέλα 20 έως 80 δισεκατομμυρίων παραμέτρων, είμαστε τρεις έως πέντε φορές πιο γρήγοροι.
- Κόστος: Η βελτιωμένη απόδοση μπορεί να μεταφραστεί σε σημαντικά μειωμένο κόστος εκπαίδευσης. Για παράδειγμα, για να εκπαιδεύσετε ένα μοντέλο με 20 δισεκατομμύρια παραμέτρους, το DeepSpeed απαιτεί τρεις φορές λιγότερους πόρους.
- Ευχρηστία: Απαιτούνται μόνο μερικές γραμμές αλλαγών κώδικα για να μπορέσει ένα μοντέλο PyTorch να χρησιμοποιεί DeepSpeed και ZeRO. Σε σύγκριση με τις τρέχουσες βιβλιοθήκες παραλληλισμού μοντέλων, το DeepSpeed δεν απαιτεί επανασχεδιασμό κώδικα ή ανακατασκευή μοντέλου.
Η Microsoft διαθέτει open source τόσο DeepSpeed όσο και ZeRO, μπορείτε να το ελέγξετε εδώ στο GitHub.
πηγή: Microsoft