Microsoft veröffentlicht eine Ursachenanalyse für die großen Microsoft 365-Anmeldeprobleme dieser Woche
![]() 6 Minute. lesen
6 Minute. lesen
![]() Aktualisiert am
Aktualisiert am
Teile diesen Artikel

Verbessern Sie diesen Leitfaden
Lesen Sie unsere Offenlegungsseite, um herauszufinden, wie Sie MSPoweruser dabei helfen können, das Redaktionsteam zu unterstützen Lesen Sie weiter
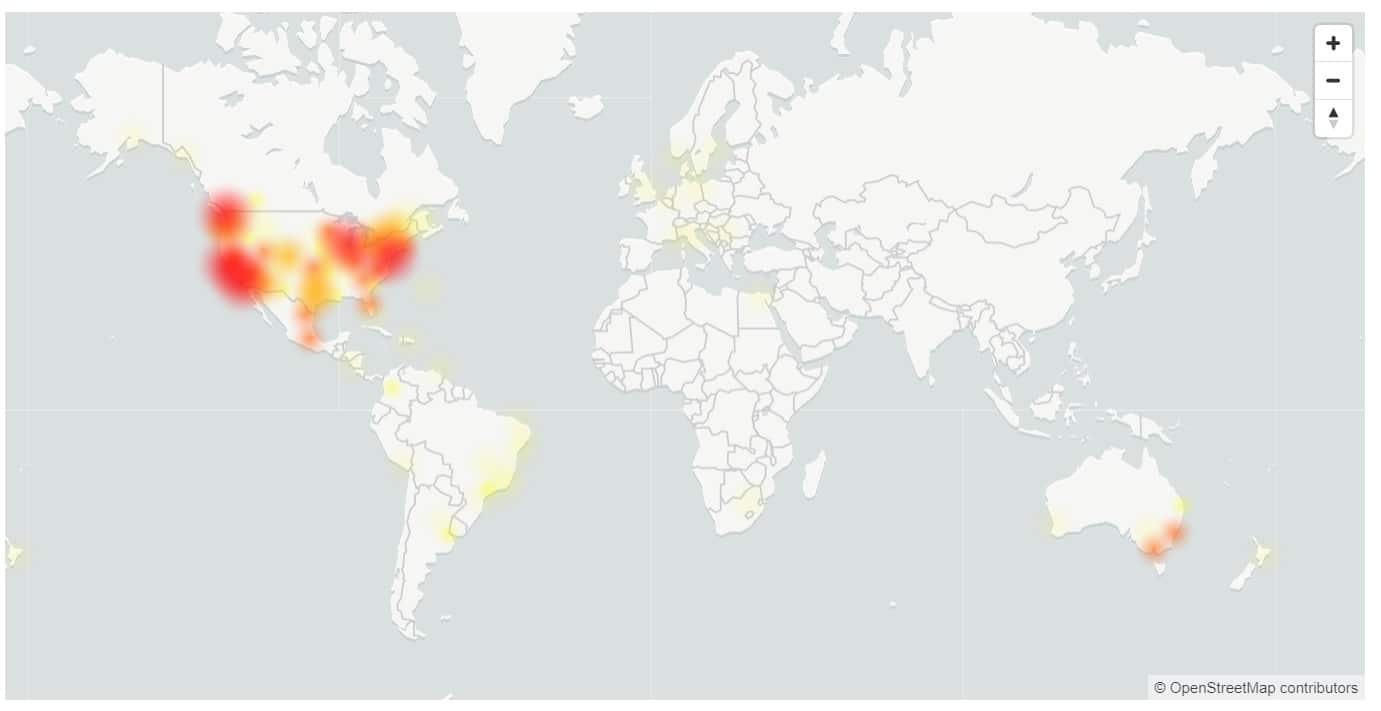
Diese Woche hatten wir eine fast 5-stündige Ausfallzeit für Microsoft 365, mit Benutzern, die sich nicht bei mehreren Diensten anmelden können, einschließlich OneDrive und Microsoft Teams.
Heute Microsoft hat eine Ursachenanalyse des Problems veröffentlicht, das laut Microsoft auf ein Dienstupdate zurückzuführen war, das auf einen internen Validierungstestring abzielen sollte, aber stattdessen aufgrund eines latenten Codefehlers im System des sicheren Bereitstellungsprozesses (SDP) des Azure AD-Backend-Dienstes direkt in der Produktionsumgebung von Microsoft bereitgestellt wurde.
Laut Microsoft sind Kunden zwischen dem 21. September 25 um 28:2020 UTC und dem 00. September 23 um 29:2020 UTC auf Fehler gestoßen, als sie Authentifizierungsvorgänge für alle Anwendungen und Dienste von Microsoft und Drittanbietern durchgeführt haben, die von Azure Active Directory (Azure AD ) zur Authentifizierung. Erst um 2:25 Uhr am nächsten Tag war das Problem für alle vollständig behoben.
Die USA und Australien waren am stärksten betroffen, wobei sich nur 17 % der Benutzer in den USA erfolgreich anmelden konnten.
Das Problem wurde dadurch verschlimmert, dass Microsoft das Update aufgrund des latenten Fehlers in seinem SDP-System, der die Bereitstellungsmetadaten beschädigte, nicht zurücksetzen konnte, was bedeutet, dass das Update manuell zurückgesetzt werden musste.
Microsoft entschuldigte sich bei den betroffenen Kunden und sagte, dass sie weiterhin Schritte unternehmen, um die Microsoft Azure-Plattform und ihre Prozesse zu verbessern, um sicherzustellen, dass solche Vorfälle in Zukunft nicht mehr auftreten. Einer der geplanten Schritte umfasst das Anwenden zusätzlicher Schutzmaßnahmen auf das SDP-System des Azure AD-Dienst-Back-Ends, um die identifizierten Probleme zu verhindern.
Lesen Sie die vollständige Analyse unten:
RCA – Authentifizierungsfehler bei mehreren Microsoft-Diensten und in Azure Active Directory integrierten Anwendungen (Tracking-ID SM79-F88)
Zusammenfassung der Auswirkungen: Zwischen etwa 21:25 UTC am 28. September 2020 und 00:23 UTC am 29. September 2020 sind Kunden möglicherweise auf Fehler bei der Durchführung von Authentifizierungsvorgängen für alle Anwendungen und Dienste von Microsoft und Drittanbietern gestoßen, die von Azure Active Directory (Azure AD) abhängen. zur Authentifizierung. Auch Anwendungen, die Azure AD B2C zur Authentifizierung verwenden, waren betroffen.
Bei Benutzern, die noch nicht mit Azure AD bei Clouddiensten authentifiziert wurden, traten mit größerer Wahrscheinlichkeit Probleme auf, und möglicherweise wurden mehrere Authentifizierungsanforderungsfehler festgestellt, die den unten gezeigten durchschnittlichen Verfügbarkeitszahlen entsprechen. Diese wurden über verschiedene Kunden und Workloads hinweg aggregiert.
- Europa: 81 % Erfolgsquote für die Dauer des Vorfalls.
- Amerika: 17 % Erfolgsquote für die Dauer des Vorfalls, Verbesserung auf 37 % kurz vor der Schadensbegrenzung.
- Asien: 72 % Erfolgsquote in den ersten 120 Minuten des Vorfalls. Als der Spitzenverkehr während der Geschäftszeiten begann, sank die Verfügbarkeit auf ihren niedrigsten Wert von 32 %.
- Australien: 37 % Erfolgsquote für die Dauer des Vorfalls.
Der Dienst wurde für die Mehrheit der Kunden am 00. September 23 um 29:2020 UTC wieder auf die normale Betriebsverfügbarkeit zurückgesetzt, wir beobachteten jedoch gelegentliche Fehler bei Authentifizierungsanforderungen, die sich möglicherweise bis 02:25 UTC auf Kunden ausgewirkt haben.
Bei Benutzern, die sich vor der Startzeit der Auswirkung authentifiziert hatten, traten mit geringerer Wahrscheinlichkeit Probleme auf, je nachdem, auf welche Anwendungen oder Dienste sie zugegriffen haben.
Durch Resilienzmaßnahmen wurden Managed Identities-Dienste für virtuelle Maschinen, VM-Skalierungsgruppen und Azure Kubernetes-Dienste mit einer durchschnittlichen Verfügbarkeit von 99.8 % während der Dauer des Vorfalls geschützt.
Ursache: Am 28. September um 21:25 UTC wurde ein Dienstupdate bereitgestellt, das auf einen internen Validierungstestring abzielte und beim Start in den Azure AD-Back-End-Diensten einen Absturz verursachte. Ein latenter Codefehler im SDP-System (Safe Deployment Process) des Azure AD-Back-End-Dienstes führte dazu, dass dieser direkt in unserer Produktionsumgebung bereitgestellt wurde, wodurch unser normaler Validierungsprozess umgangen wurde.
Azure AD ist als geografisch verteilter Dienst konzipiert, der in einer Aktiv-Aktiv-Konfiguration mit mehreren Partitionen in mehreren Rechenzentren auf der ganzen Welt bereitgestellt wird und mit Isolationsgrenzen erstellt wurde. Normalerweise zielen Änderungen zunächst auf einen Validierungsring ab, der keine Kundendaten enthält, gefolgt von einem inneren Ring, der nur Microsoft-Benutzer enthält, und schließlich auf unsere Produktionsumgebung. Diese Änderungen werden in Phasen über mehrere Tage in fünf Ringen bereitgestellt.
In diesem Fall konnte das SDP-System aufgrund eines latenten Fehlers, der die Fähigkeit des Systems zur Interpretation von Bereitstellungsmetadaten beeinträchtigte, den Validierungstestring nicht korrekt anvisieren. Folglich wurden alle Ringe gleichzeitig anvisiert. Die falsche Bereitstellung führte zu einer Verschlechterung der Dienstverfügbarkeit.
Innerhalb von Minuten nach der Auswirkung haben wir Schritte unternommen, um die Änderung mithilfe automatisierter Rollback-Systeme rückgängig zu machen, die normalerweise die Dauer und Schwere der Auswirkung begrenzt hätten. Der latente Fehler in unserem SDP-System hatte jedoch die Bereitstellungsmetadaten beschädigt, und wir mussten auf manuelle Rollback-Prozesse zurückgreifen. Dadurch verlängerte sich die Zeit zur Behebung des Problems erheblich.
Schadensbegrenzung: Unsere Überwachung hat die Serviceverschlechterung innerhalb von Minuten nach der ersten Auswirkung erkannt, und wir haben sofort mit der Fehlerbehebung begonnen. Folgende Minderungsmaßnahmen wurden durchgeführt:
- Der Einschlag begann um 21:25 UTC und innerhalb von 5 Minuten entdeckte unsere Überwachung einen ungesunden Zustand und die Technik wurde sofort eingeschaltet.
- In den nächsten 30 Minuten wurde gleichzeitig mit der Fehlerbehebung des Problems eine Reihe von Schritten unternommen, um zu versuchen, die Auswirkungen auf den Kunden zu minimieren und die Schadensbegrenzung zu beschleunigen. Dazu gehörte das proaktive Hochskalieren einiger der Azure AD-Dienste, um die erwartete Last zu bewältigen, sobald eine Risikominderung angewendet worden wäre, und ein Failover bestimmter Workloads auf ein Backup-Azure AD-Authentifizierungssystem.
- Um 22:02 UTC stellten wir die Grundursache fest, begannen mit der Behebung und leiteten unsere automatisierten Rollback-Mechanismen ein.
- Das automatische Rollback ist aufgrund der Beschädigung der SDP-Metadaten fehlgeschlagen. Um 22:47 UTC haben wir den Prozess zur manuellen Aktualisierung der Dienstkonfiguration eingeleitet, die das SDP-System umgeht, und der gesamte Vorgang wurde um 23:59 UTC abgeschlossen.
- Um 00:23 UTC kehrten genügend Back-End-Dienstinstanzen in einen fehlerfreien Zustand zurück, um die normalen Betriebsparameter des Dienstes zu erreichen.
- Alle Dienstinstanzen mit verbleibenden Auswirkungen wurden um 02:25 UTC wiederhergestellt.
Nächste Schritte: Wir entschuldigen uns aufrichtig für die Auswirkungen bei den betroffenen Kunden. Wir unternehmen kontinuierlich Schritte zur Verbesserung der Microsoft Azure-Plattform und unserer Prozesse, um sicherzustellen, dass solche Vorfälle in Zukunft nicht mehr auftreten. In diesem Fall umfasst dies Folgendes (ist jedoch nicht darauf beschränkt):
Wir haben bereits abgeschlossen
- Der latente Codefehler im SDP-System des Azure AD-Backends wurde behoben.
- Das vorhandene Rollback-System wurde korrigiert, um die Wiederherstellung der letzten als funktionierend bekannten Metadaten zum Schutz vor Beschädigung zu ermöglichen.
- Erweitern Sie den Umfang und die Häufigkeit von Rollback-Vorgangsübungen.
Die verbleibenden Schritte umfassen
- Wenden Sie zusätzliche Schutzmaßnahmen auf das Back-End-SDP-System des Azure AD-Diensts an, um die hier identifizierte Klasse von Problemen zu verhindern.
- Beschleunigen Sie die Einführung des Azure AD-Sicherungsauthentifizierungssystems für alle wichtigen Dienste als oberste Priorität, um die Auswirkungen ähnlicher Probleme in Zukunft erheblich zu reduzieren.
- Integrieren Sie Azure AD-Szenarien in die automatisierte Kommunikationspipeline, die die erste Mitteilung an betroffene Kunden innerhalb von 15 Minuten nach der Auswirkung sendet.
Rückmeldung geben: Bitte helfen Sie uns, die Azure-Kundenkommunikation zu verbessern, indem Sie an unserer Umfrage teilnehmen: https://aka.ms/AzurePIRSurvey