Microsoft DeBERTa overgår sølle mennesker i SuperGlue læseforståelsestest
![]() 2 min. Læs
2 min. Læs
![]() Udgivet den
Udgivet den
Del denne artikel

Forbedre denne vejledning
Læs vores oplysningsside for at finde ud af, hvordan du kan hjælpe MSPoweruser med at opretholde redaktionen Læs mere
Der har været massive fremskridt for nylig inden for træningsnetværk med millioner af parametre. Microsoft opdaterede for nylig DeBERTa (Decoding-enhanced BERT with disentangled attention)-modellen ved at træne en større version, der består af 48 Transformer-lag med 1.5 milliarder parametre. Det betydelige præstationsboost gør, at den enkelte DeBERTa-model overgår den menneskelige præstation på SuperGLUE-sprogbehandlingen og -forståelsen for første gang i form af makrogennemsnitlig score (89.9 versus 89.8), og overgår den menneskelige baseline med en anstændig margin (90.3 versus 89.8) . SuperGLUE benchmark består af en bred vifte af Natural Language Understanding-opgaver, herunder besvarelse af spørgsmål, naturlig sprogslutning. Modellen ligger også i toppen af GLUE-benchmark-ranglisten med en makrogennemsnitlig score på 90.8.
DeBERTa forbedrer tidligere state-of-the-art PLM'er (for eksempel BERT, RoBERTa, UniLM) ved hjælp af tre nye teknikker: en løsnet opmærksomhedsmekanisme, en forbedret maskedekoder og en virtuel modstridende træningsmetode til finjustering.
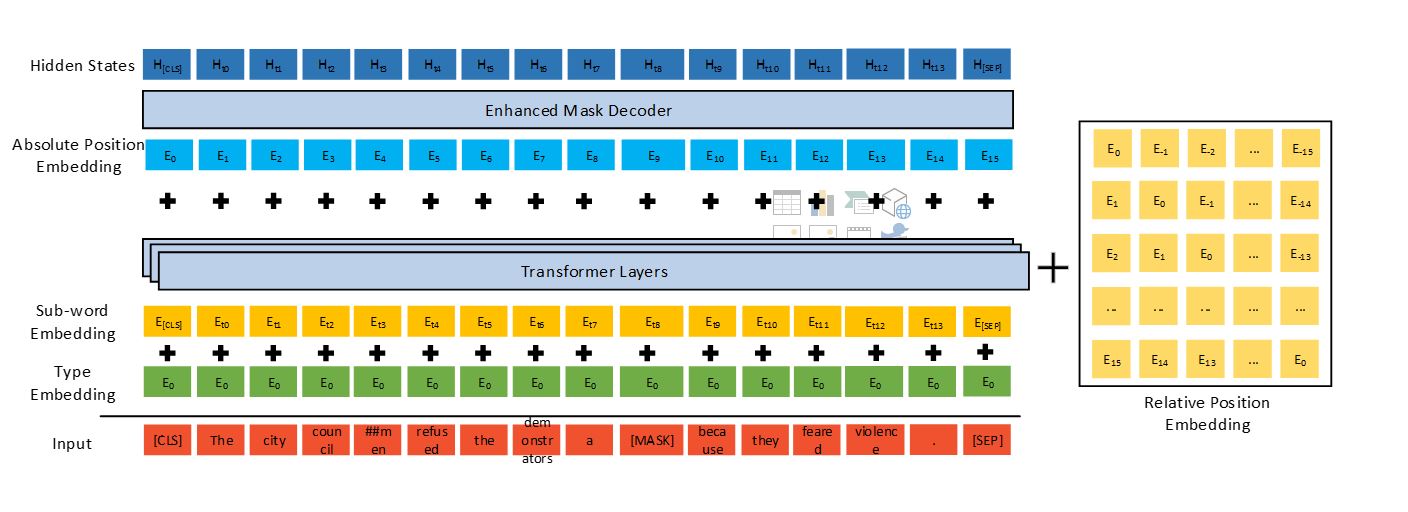
Sammenlignet med Googles T5-model, som består af 11 milliarder parametre, er DeBERTa med 1.5 milliarder parametre meget mere energieffektiv at træne og vedligeholde, og den er nemmere at komprimere og implementere til apps med forskellige indstillinger.
DeBERTa, der overgår menneskelig præstation på SuperGLUE, markerer en vigtig milepæl i retning af generel kunstig intelligens. På trods af dets lovende resultater på SuperGLUE, når modellen på ingen måde NLUs intelligens på menneskeligt niveau. Mennesker er ekstremt gode til at udnytte den viden, man har lært fra forskellige opgaver, til at løse en ny opgave med ingen eller lidt opgavespecifik demonstration.
Microsoft vil integrere teknologien i den næste version af Microsoft Turing-repræsentationsmodellen for naturligt sprog, der bruges på steder som Bing, Office, Dynamics og Azure Cognitive Services, der driver en lang række scenarier, der involverer menneske-maskine og menneske-menneske interaktioner via naturligt sprog (såsom chatbot, anbefaling, besvarelse af spørgsmål, søgning, personlig assistance, automatisering af kundesupport, generering af indhold og andre). Derudover vil Microsoft frigive DeBERTa-modellen på 1.5 milliarder parametre og kildekoden til offentligheden.
Læs alle detaljerne hos Microsoft link..