Claude 3真的比GPT-4更好吗? Promptbase 的基准测试显示不同
头对头测试显示,GPT-4 Turbo 在所有类别中均优于 Claude 3。
![]() 2分钟读
2分钟读
![]() 更新
更新
分享此文章

改进本指南
重点说明
- Anthropic 最近推出了 Claude 3,据称其性能优于 GPT-4 和 Google Gemini 1.0 Ultra。
- 发布的基准分数表明,与同类产品相比,Claude 3 Opus 在各个领域都表现出色。
- 然而,进一步的分析表明,在直接比较中,GPT-4 Turbo 的表现优于 Claude 3,这意味着报告的结果存在潜在偏差。

人择刚刚 推出克劳德3 不久前,其AI模型据说能够击败OpenAI的GPT-4和Google Gemini 1.0 Ultra。它具有三种变体:Claude 3 Haiku、Sonnet 和 Opus,均用于不同的用途。
在其 初步公告AI公司表示,Claude 3略优于这两款最近推出的机型。
根据发布的基准分数,Claude 3 Opus 在本科水平知识(MMLU)、研究生水平推理(GPQA)、小学数学和数学问题解决、多语言数学、编码、文本推理等方面表现更好优于 GPT-4 和 Gemini 1.0 Ultra 和 Pro。
然而,这并不能完全真实地描绘出整个画面。公告中发布的基准分数(尤其是 GPT-4)显然取自去年 4 年 2023 月发布版本的 GPT-XNUMX(归功于 AI 爱好者) @TolgaBilge_ 在 X 上)
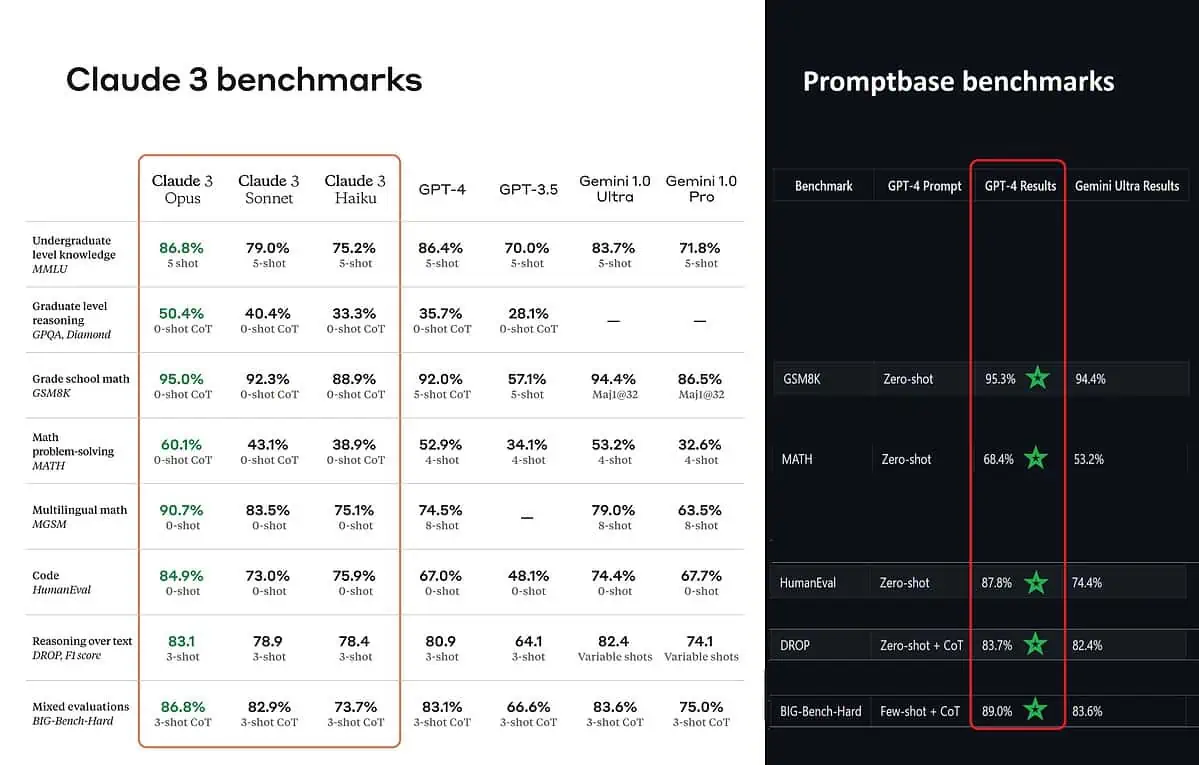
一种分析性能的工具(基准分析器)称为 提示库 表明 GPT-4 Turbo 实际上确实在所有可以直接比较的测试中击败了 Claude 3。这些测试涵盖基本数学技能(GSM8K 和 MATH)、编写代码(HumanEval)、文本推理(DROP)以及其他挑战。
在宣布结果的同时,Anthropic 还 脚注中提到 他们的工程师能够通过专门针对测试进行微调来进一步提高 GPT-4T 的性能。这表明报告的结果可能无法反映基本模型的真实功能。
哎哟。





用户论坛
0消息