Зустрічайте Microsoft DeepSpeed, нову бібліотеку глибокого навчання, яка може навчати величезні моделі зі 100 мільярдами параметрів
![]() 2 хв. читати
2 хв. читати
![]() Оновлено на
Оновлено на
Поділитися цією статтею

Удосконалити цей посібник
Прочитайте нашу сторінку розкриття інформації, щоб дізнатися, як ви можете допомогти MSPoweruser підтримувати редакційну команду Читати далі
Сьогодні Microsoft Research анонсувала DeepSpeed, нову бібліотеку оптимізації глибокого навчання, яка може навчати величезні моделі зі 100 мільярдами параметрів. У ШІ вам потрібно мати більші моделі природної мови для кращої точності. Але навчання більших моделей природної мови займає багато часу, а пов’язані з цим витрати дуже високі. Microsoft стверджує, що нова бібліотека глибокого навчання DeepSpeed покращує швидкість, вартість, масштаб і зручність використання.
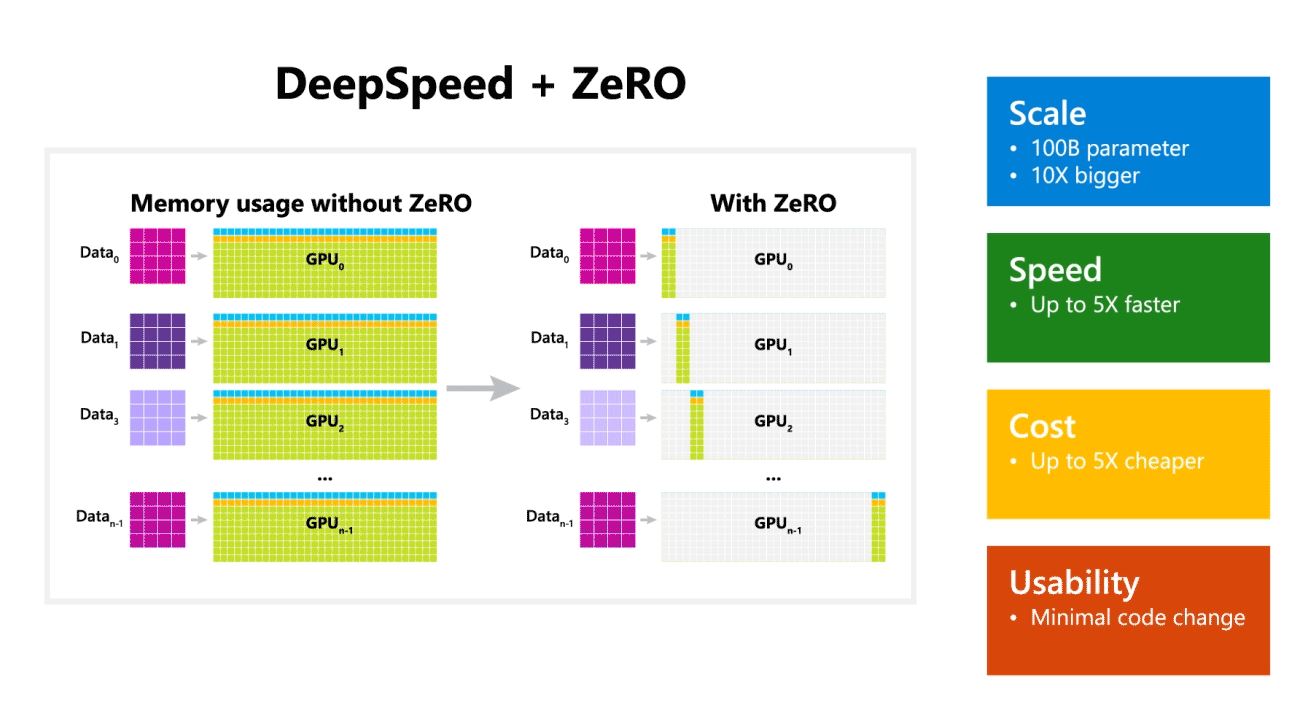
Microsoft також зазначила, що DeepSpeed дозволяє мовні моделі з моделями до 100 мільярдів параметрів і включає ZeRO (Zero Redundancy Optimizer), паралельний оптимізатор, який зменшує ресурси, необхідні для паралельності моделей і даних, одночасно збільшуючи кількість параметрів, які можна навчати. . Використовуючи DeepSpeed і ZeRO, дослідники Microsoft розробили нову генерацію природної мови Turing (Turing-NLG), найбільшу мовну модель із 17 мільярдами параметрів.
Основні моменти DeepSpeed:
- шкала: Найсучасніші великі моделі, такі як OpenAI GPT-2, NVIDIA Megatron-LM і Google T5, мають розміри 1.5 мільярда, 8.3 мільярда та 11 мільярдів параметрів відповідно. Перший етап ZeRO в DeepSpeed забезпечує системну підтримку для запуску моделей з до 100 мільярдів параметрів, що в 10 разів більше.
- швидкість: Ми спостерігаємо до п'яти разів вищу пропускну здатність у порівнянні з найсучаснішим обладнанням. На кластерах графічних процесорів NVIDIA з низькопропускним підключенням (без NVIDIA NVLink або Infiniband) ми досягаємо підвищення пропускної здатності в 3.75 рази порівняно з використанням лише Megatron-LM для стандартної моделі GPT-2 з 1.5 мільярдами параметрів. На кластерах NVIDIA DGX-2 з високошвидкісним з’єднанням для моделей з параметрами від 20 до 80 мільярдів ми працюємо в три-п’ять разів швидше.
- Коштувати: Покращена пропускна здатність може бути переведена на істотне зниження вартості навчання. Наприклад, щоб навчити модель з 20 мільярдами параметрів, DeepSpeed потрібно втричі менше ресурсів.
- Юзабіліті: Для того, щоб модель PyTorch могла використовувати DeepSpeed і ZeRO, потрібно лише кілька рядків змінити код. У порівнянні з поточними бібліотеками паралелізму моделей, DeepSpeed не вимагає переробки коду або рефакторингу моделі.
Microsoft пропонує відкритий вихідний код як DeepSpeed, так і ZeRO, ви можете перевірити це тут на GitHub.
джерело: Microsoft