Чи дійсно Claude 3 кращий за GPT-4? Порівняльний аналіз Promptbase говорить про інше
Прямі випробування показали, що GPT-4 Turbo випереджає Claude 3 у всіх категоріях.
![]() 2 хв. читати
2 хв. читати
![]() Оновлено на
Оновлено на
Поділитися цією статтею

Удосконалити цей посібник
Прочитайте нашу сторінку розкриття інформації, щоб дізнатися, як ви можете допомогти MSPoweruser підтримувати редакційну команду Читати далі
Основні нотатки
- Нещодавно компанія Anthropic випустила Claude 3, який, як рекламується, перевершить GPT-4 і Google Gemini 1.0 Ultra.
- Опубліковані порівняльні результати вказують на те, що Claude 3 Opus перевершує в різних сферах порівняно зі своїми аналогами.
- Проте подальший аналіз показує, що GPT-4 Turbo перевершує Claude 3 у прямих порівняннях, що свідчить про потенційні упередження в звітних результатах.

Антропік щойно запустив Claude 3 Не так давно його модель штучного інтелекту, яка, як кажуть, здатна перемогти OpenAI GPT-4 і Google Gemini 1.0 Ultra. Він поставляється з трьома варіантами: хайку Клода 3, сонет і опус, усі для різного використання.
У своїй початкове оголошення, компанія AI каже, що Claude 3 трохи перевершує ці дві нещодавно випущені моделі.
Згідно з опублікованими контрольними показниками, Claude 3 Opus є кращим у знаннях студентського рівня (MMLU), міркуванні на рівні магістратури (GPQA), математиці початкової школи та розв’язанні математичних задач, багатомовній математиці, кодуванні, міркуванні над текстом тощо. ніж GPT-4 і Gemini 1.0 Ultra і Pro.
Однак це не повністю відображає всю картину. Опублікований контрольний показник в оголошенні (особливо для GPT-4) очевидно був узятий з GPT-4 у версії випуску від березня 2023 року минулого року (заслуга ентузіастів штучного інтелекту @TolgaBilge_ на X)
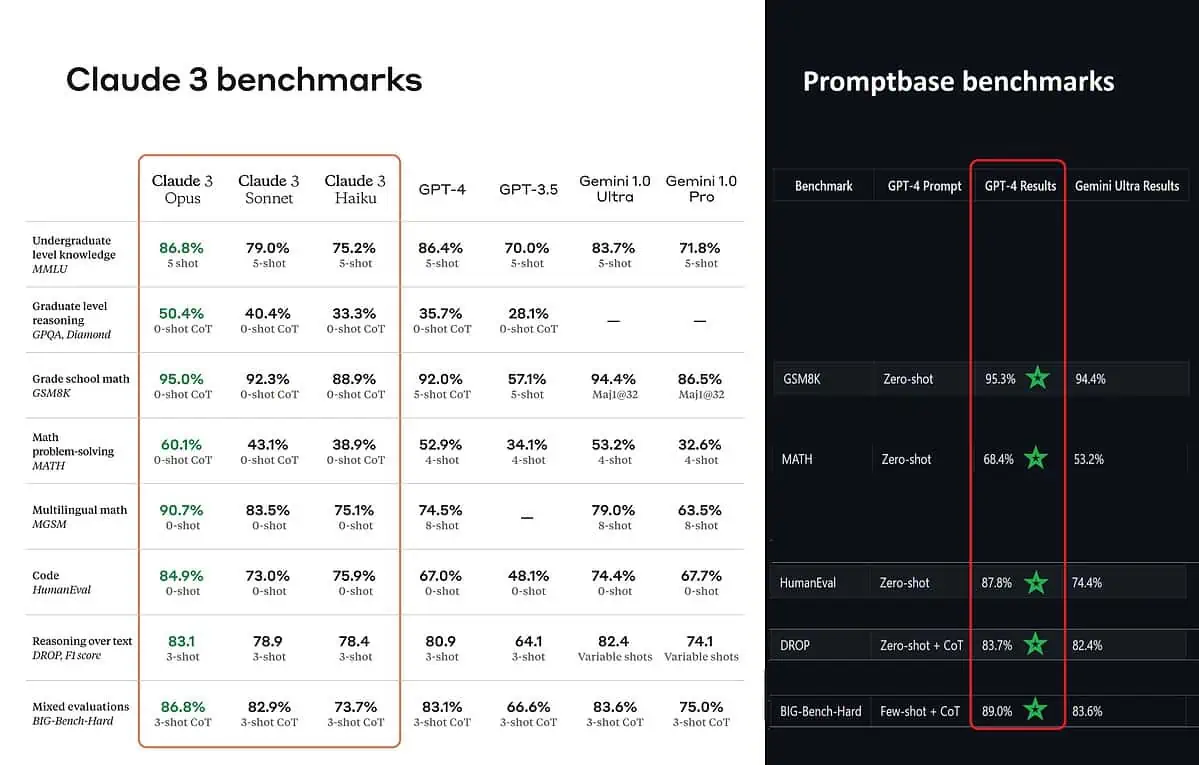
Інструмент, який аналізує продуктивність (бенчмарк аналізатор) називається Promptbase показує, що GPT-4 Turbo справді перемагає Claude 3 у всіх тестах, у яких вони могли порівнювати їх безпосередньо. Ці тести охоплюють базові математичні навички (GSM8K & MATH), написання коду (HumanEval), міркування над текстом (DROP) і низку інших завдань.
Оголошуючи свої результати, Anthropic також згадки у виносці що їхні інженери змогли ще більше покращити продуктивність GPT-4T, налаштувавши її спеціально для тестів. Це свідчить про те, що надані результати можуть не відображати справжні можливості базової моделі.
Ой!





Форум користувачів
0 повідомлення