Генератор тексту в зображення від Google Imagen створює зображення з «безпрецедентним ступенем фотореалізму»
![]() 3 хв. читати
3 хв. читати
![]() Опубліковано
Опубліковано
Поділитися цією статтею

Удосконалити цей посібник
Прочитайте нашу сторінку розкриття інформації, щоб дізнатися, як ви можете допомогти MSPoweruser підтримувати редакційну команду Читати далі
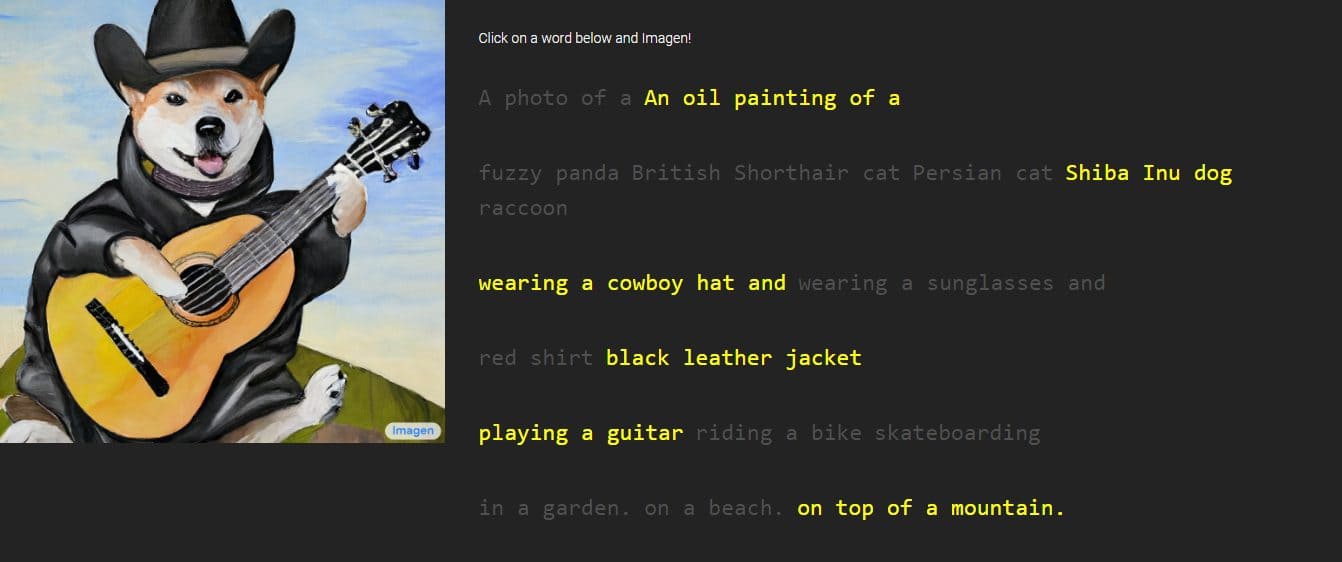
Google представила нове творіння під назвою «Зображення», генератор тексту в зображення через описи, які надасть людина. Компанія стверджує, що вона перевершує продуктивність DALL-E 2, іншого генератора зображень AI. У ньому були представлені деякі зразки, які, безсумнівно, демонструють вишукані деталі, але Imagen наразі недоступний для громадськості.
Описується, що нова модель дифузії тексту в зображення має «безпрецедентний ступінь фотореалізму та глибокий рівень розуміння мови». Він розуміє текст за допомогою великих мовних моделей-трансформаторів і, як кажуть, покладається на моделі дифузії для створення високоякісного зображення.

Google надав зображення та зразки робіт Imagen із різними стилями від малюнків до картин маслом та CGI. Вони супроводжуються словами та фразами, які використовуються для їх створення. Наприклад, в одному зразку написано: «плід дракона, одягнений у пояс для карате на снігу», а в іншому — «маленький кактус у солом’яному капелюсі й неонових сонцезахисних окулярах у пустелі Сахара».
Згенеровані зображення виглядають неймовірно реальними, ніби їх створила реальна людина. Однак Google стверджує, що це робиться за допомогою дифузійних технологій, використовуючи зображення чистого шуму та покращуючи його найкращим можливим способом. Зрозумівши наданий текстовий опис, Imagen створить зображення розміром 64 x 64 пікселі, виконає два покращення та перетворить зображення на більший фрагмент розміром 1024 x 1024 пікселя.
Google Research, Brain Team каже, що Imagen досягла успіху Коко (великомасштабний набір даних виявлення, сегментації та субтитрів), незважаючи на те, що ви не навчені цьому. Команда повідомила, що отримала новий найсучасніший бал FID 7.27.
Google також порівняв продуктивність Imagen з іншими моделями текст-зображення, оцінивши їх за допомогою «DrawBench». Він служить еталоном для моделей текст-зображення, де Google тестував Imagen за допомогою інших методів, таких як VQ-GAN+CLIP, Latent Diffusion Models та DALL-E 2. Після тестування їх композиційності, потужності, просторових відносин, довгої форми текст, рідкісні слова та складні підказки, команда зазначила, що «теперці надають перевагу Imagen перед іншими методами, як у вирівнюванні зображення-текст, так і в точності зображення».
Незважаючи на ці вражаючі звіти дослідницької групи, самостійно протестувати Imagen буде неможливо, оскільки він недоступний для громадськості. У Google є причини для цього, такі як етичні проблеми, потенційні ризики зловживання, соціальні упередження, обмеження великих мовних моделей та ризик закодованих шкідливих стереотипів і уявлень. Команда підсумовує, що з усіма цими проблемами Imagen все ще не ідеальний, коли справа доходить до створення зображень, пов’язаних з людьми.
«Imagen має серйозні обмеження при створенні зображень із зображенням людей», — пояснює команда в повідомленні в блозі. «Наші оцінки людей показали, що Imagen отримує значно вищі показники переваг при оцінці зображень, які не зображують людей, що вказує на погіршення точності зображення. Попередня оцінка також припускає, що Imagen кодує кілька соціальних упереджень і стереотипів, включаючи загальне упередження щодо створення образів людей зі світлими тонами шкіри та тенденцію до того, щоб зображення, що зображують різні професії, відповідали західним гендерним стереотипам. Нарешті, навіть коли ми зосереджуємо покоління далеко від людей, наш попередній аналіз показує, що Imagen кодує цілий ряд соціальних і культурних упереджень при створенні образів діяльності, подій та об’єктів. Ми прагнемо досягти прогресу в деяких із цих відкритих проблем і обмежень у майбутній роботі».