100 milyar parametrelik devasa modelleri eğitebilen yeni bir derin öğrenme kitaplığı olan Microsoft DeepSpeed ile tanışın
![]() 2 dk. okuman
2 dk. okuman
![]() Tarihinde güncellendi
Tarihinde güncellendi
Bu makaleyi paylaş

Bu kılavuzu geliştirin
MSPoweruser'ın editör ekibini ayakta tutmasına nasıl yardımcı olabileceğinizi öğrenmek için açıklama sayfamızı okuyun. Daha fazla
Microsoft Research bugün, 100 milyar parametrelik devasa modelleri eğitebilen yeni bir derin öğrenme optimizasyon kitaplığı olan DeepSpeed'i duyurdu. AI'da, daha iyi doğruluk için daha büyük doğal dil modellerine sahip olmanız gerekir. Ancak daha büyük doğal dil modellerini eğitmek zaman alıcıdır ve bununla ilişkili maliyetler çok yüksektir. Microsoft, yeni DeepSpeed derin öğrenme kitaplığının hızı, maliyeti, ölçeği ve kullanılabilirliği iyileştirdiğini iddia ediyor.
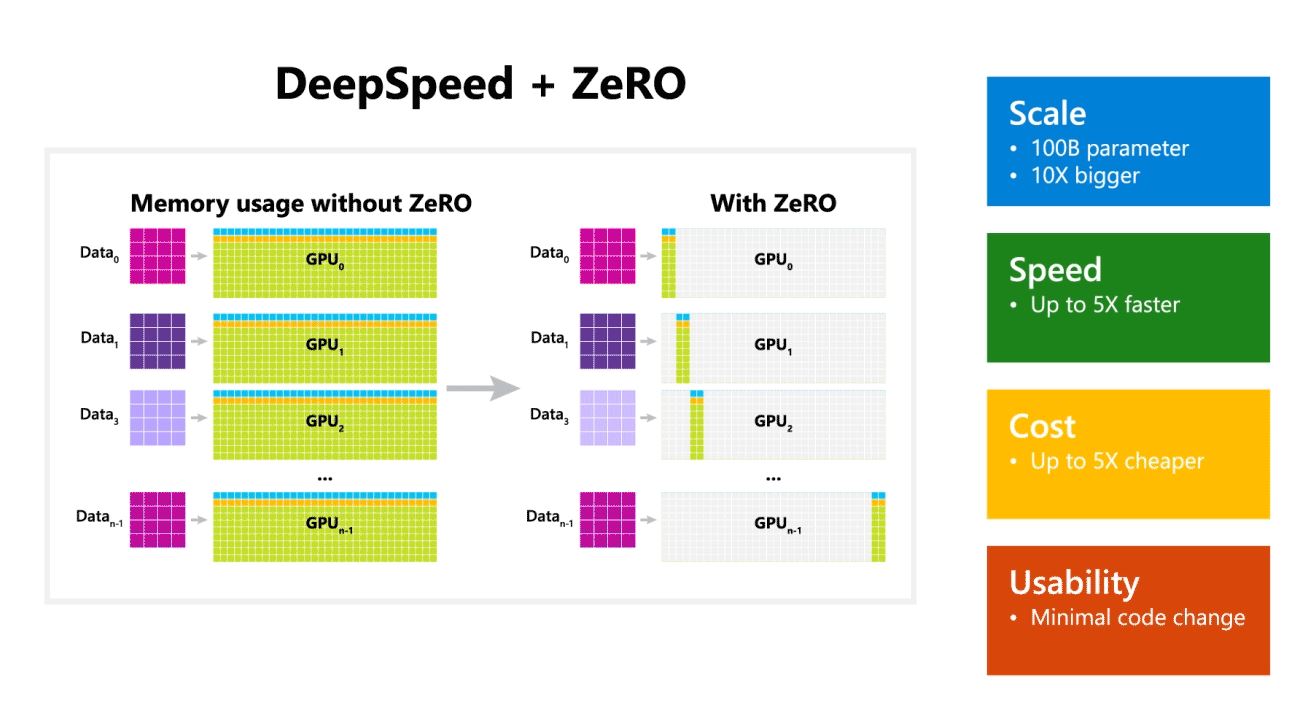
Microsoft ayrıca DeepSpeed'in 100 milyar parametreye kadar modele sahip dil modellerini etkinleştirdiğini ve model ve veri paralelliği için gereken kaynakları azaltırken eğitilebilecek parametre sayısını artıran paralelleştirilmiş bir optimize edici olan ZeRO'yu (Zero Redundancy Optimizer) içerdiğini belirtti. . Microsoft Araştırmacıları, DeepSpeed ve ZeRO kullanarak 17 milyar parametreye sahip en büyük dil modeli olan yeni Turing Natural Language Generation'ı (Turing-NLG) geliştirdi.
DeepSpeed'in öne çıkan özellikleri:
- ölçek: OpenAI GPT-2, NVIDIA Megatron-LM ve Google T5 gibi son teknoloji büyük modellerin boyutları sırasıyla 1.5 milyar, 8.3 milyar ve 11 milyar parametreye sahiptir. DeepSpeed'deki ZeRO birinci aşama, 100 kat daha büyük, 10 milyar parametreye kadar modelleri çalıştırmak için sistem desteği sağlar.
- hız: Çeşitli donanımlarda son teknolojiye göre beş kata kadar daha yüksek verim gözlemliyoruz. Düşük bant genişliğine sahip ara bağlantıya sahip NVIDIA GPU kümelerinde (NVIDIA NVLink veya Infiniband olmadan), 3.75 milyar parametreli standart bir GPT-2 modeli için tek başına Megatron-LM kullanmaya kıyasla 1.5 kat verim artışı elde ediyoruz. Yüksek bant genişliğine sahip ara bağlantıya sahip NVIDIA DGX-2 kümelerinde, 20 ila 80 milyar parametreli modeller için üç ila beş kat daha hızlıyız.
- Ücret: Geliştirilmiş çıktı, önemli ölçüde azaltılmış eğitim maliyetine dönüştürülebilir. Örneğin, 20 milyar parametreli bir modeli eğitmek için DeepSpeed üç kat daha az kaynak gerektirir.
- Kullanılabilirlik: Bir PyTorch modelinin DeepSpeed ve ZeRO kullanmasını sağlamak için yalnızca birkaç satır kod değişikliği gereklidir. Mevcut model paralellik kitaplıkları ile karşılaştırıldığında, DeepSpeed, kodun yeniden tasarımı veya modelin yeniden düzenlenmesi gerektirmez.
Microsoft, hem DeepSpeed hem de ZeRO'yu açık kaynak olarak kullanıyor, kontrol edebilirsiniz GitHub'da.
Kaynak: Microsoft