Claude 3 gerçekten GPT-4'ten daha mı iyi? Promptbase'in kıyaslaması farklı diyor
Karşılıklı testler GPT-4 Turbo'nun tüm kategorilerde Claude 3'ü geride bıraktığını gösteriyor.
![]() 2 dk. okuman
2 dk. okuman
![]() Tarihinde güncellendi
Tarihinde güncellendi
Bu makaleyi paylaş

Bu kılavuzu geliştirin
MSPoweruser'ın editör ekibini ayakta tutmasına nasıl yardımcı olabileceğinizi öğrenmek için açıklama sayfamızı okuyun. Daha fazla
Önemli notlar
- Anthropic yakın zamanda GPT-3 ve Google Gemini 4 Ultra'dan daha iyi performans gösterdiği öne sürülen Claude 1.0'ü piyasaya sürdü.
- Yayınlanan kıyaslama puanları, Claude 3 Opus'un benzerlerine kıyasla çeşitli alanlarda üstün olduğunu gösteriyor.
- Ancak daha ileri analizler, GPT-4 Turbo'nun doğrudan karşılaştırmalarda Claude 3'ten daha iyi performans gösterdiğini ortaya koyuyor ve bu da raporlanan sonuçlarda potansiyel yanlılıklar olduğunu gösteriyor.

Antropik az önce Claude 3'ü başlattı Çok uzun zaman önce, AI modelinin OpenAI'nin GPT-4'ünü ve Google Gemini 1.0 Ultra'yı yenebileceği söyleniyordu. Üç çeşidiyle birlikte gelir: Claude 3 Haiku, Sonnet ve Opus, hepsi farklı kullanımlara yönelik.
Onun içinde ilk duyuruAI şirketi, Claude 3'ün yakın zamanda piyasaya sürülen bu iki modelden biraz daha üstün olduğunu söylüyor.
Yayınlanan kıyaslama puanlarına göre Claude 3 Opus, lisans düzeyinde bilgi (MMLU), lisansüstü düzeyde akıl yürütme (GPQA), ilkokul matematik ve matematik problem çözme, çok dilli matematik, kodlama, metin üzerinden akıl yürütme ve diğer alanlarda daha iyidir. GPT-4 ve Gemini 1.0 Ultra ve Pro'dan daha iyidir.
Ancak bu, resmin tamamını tam olarak gerçeğe uygun şekilde yansıtmıyor. Duyuruda yayınlanan karşılaştırma puanı (özellikle GPT-4 için) görünüşe göre geçen yıl Mart 4'te yayımlanan sürümdeki GPT-2023'ten alınmıştır (Yapay Zeka tutkunlarına teşekkür ederiz) @TolgaBilge_ on X)
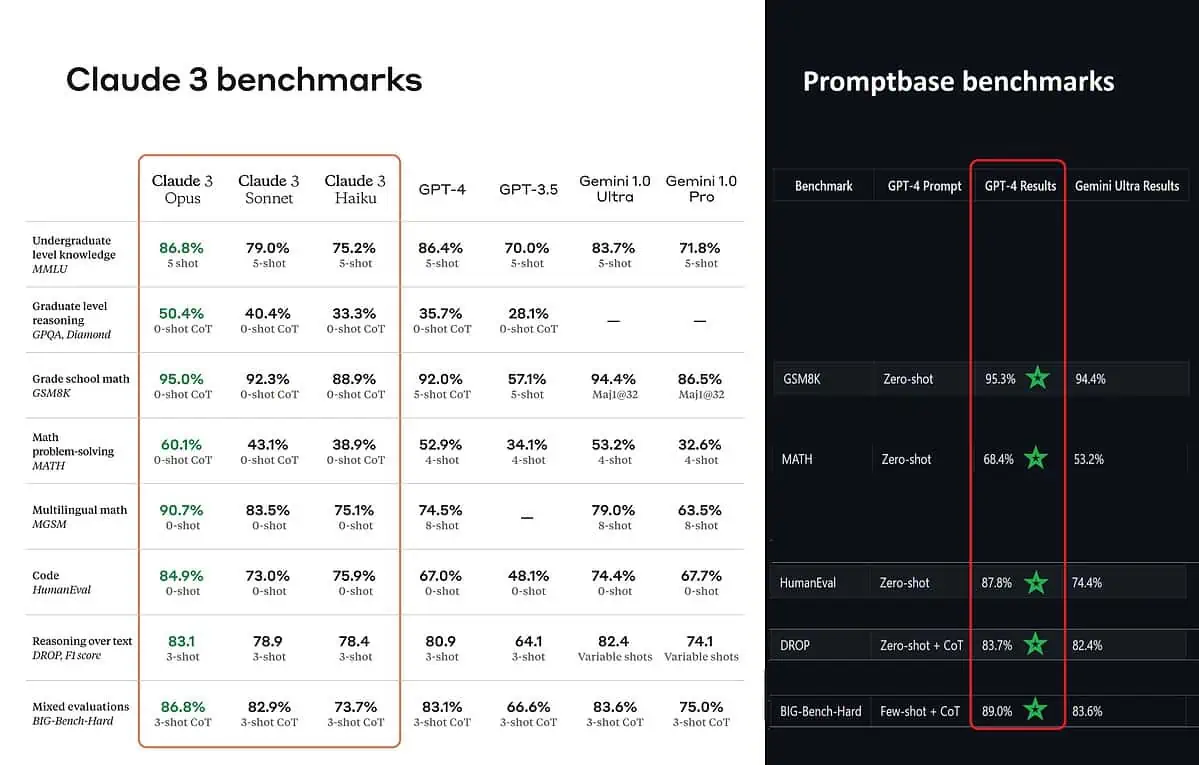
Performansı analiz eden bir araca (benchmark analizörü) adı verilir İstem tabanı GPT-4 Turbo'nun doğrudan karşılaştırabilecekleri tüm testlerde Claude 3'ü gerçekten geride bıraktığını gösteriyor. Bu testler, temel matematik becerileri (GSM8K ve MATH), kod yazma (HumanEval), metin üzerinde akıl yürütme (DROP) ve diğer zorlukların bir karışımı gibi konuları kapsar.
Anthropic, sonuçlarını açıklarken aynı zamanda dipnotta bahsediyor mühendislerinin, özellikle testler için ince ayar yaparak GPT-4T'nin performansını daha da artırabildiklerini söyledi. Bu, rapor edilen sonuçların temel modelin gerçek yeteneklerini yansıtmayabileceğini göstermektedir.
Ahh.





Kullanıcı forumu
0 mesajları