Microsoft bevisar att GPT-4 kan slå Google Gemini Ultra med hjälp av nya prompttekniker
![]() 2 min. läsa
2 min. läsa
![]() Publicerad den
Publicerad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Förra veckan meddelade Google tvillingarna, dess mest kapabla och generella modell hittills. Google Gemini-modellen levererar toppmodern prestanda över många ledande riktmärken. Google betonade att den mest kapabla Gemini Ultra-modellens prestanda överträffar OpenAI GPT-4:s resultat på 30 av de 32 allmänt använda akademiska riktmärkena som används i forskning och utveckling av stora språkmodeller (LLM).
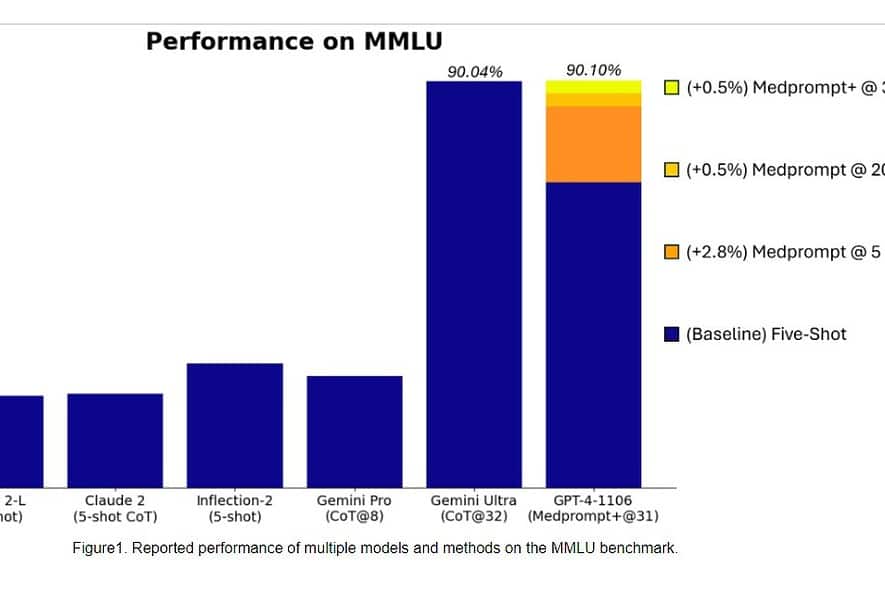
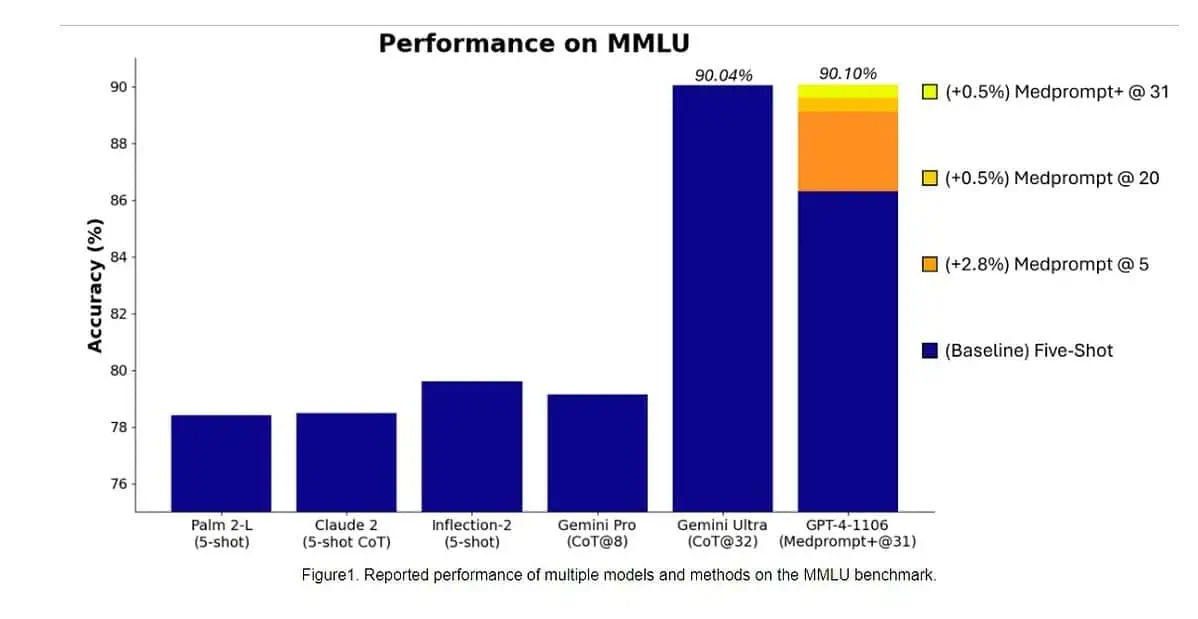
Specifikt blev Gemini Ultra den första modellen att överträffa mänskliga experter på MMLU (massiv multitask språkförståelse) med 90 % poäng, som använder en kombination av 57 ämnen som matematik, fysik, historia, juridik, medicin och etik för att testa både världskunskap och problemlösningsförmåga.
Igår, Microsoft Research-teamet avslöjade att OpenAI:s GPT-4-modell kan slå Google Gemini Ultra när nya prompttekniker används. Förra månaden avslöjade Microsoft Research Medprompt, en sammansättning av flera promptstrategier som avsevärt förbättrar GPT-4:s prestanda och uppnår toppmoderna resultat i MultiMedQA-sviten. Microsoft har nu tillämpat promptteknikerna som används i Medprompt även för allmänna domäner. Enligt Microsoft uppnår OpenAI:s GPT-4-modell när den används med en modifierad version av Medprompt den högsta poängen som någonsin uppnåtts på hela MMLU. Ja, OpenAI GPT-4 kan slå den kommande Gemini Ultra-modellen genom att bara använda uppmaningsteknikerna. Detta visar att vi ännu inte har nått den fulla potentialen hos redan släppta modeller som GPT-4.
Ta en titt på jämförelsen mellan GPT-4 (förbättrade meddelanden) och Gemini Ultra-modellerna nedan.
| riktmärke | GPT-4-prompt | GPT-4-resultat | Gemini Ultra-resultat |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Nollskott | 95.27% | 94.4% |
| MATEMATIK | Nollskott | 68.42% | 53.2% |
| HumanEval | Nollskott | 87.8% | 74.4% |
| STOR-Bänk-Hård | Few-shot + CoT* | 89.0% | 83.6% |
| FALLA | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-skott** | 95.3% | 87.8% |
Först tillämpade Microsoft den ursprungliga Medprompt på GPT-4 för att uppnå poängen på 89.1 % i MMLU. Senare ökade Microsoft antalet sammansatta samtal i Medprompt från fem till 20, vilket ledde till den ökade poängen på 89.56 %. Microsoft utökade senare Medprompt till Medprompt+ genom att lägga till en enklare promptmetod och formulera en policy för att härleda ett slutgiltigt svar genom att integrera utdata från både bas Medprompt-strategin och de enkla uppmaningarna. Detta ledde till att GPT-4 nådde ett rekordresultat på 90.10 %. Microsoft Research-teamet nämnde att Google Gemini-teamet också använde liknande uppmaningsteknik för att uppnå rekordpoängen på MMLU.
Du kan lära dig mer om prompttekniker som Microsoft använde för att slå Gemini Ultra här..