Är Claude 3 verkligen bättre än GPT-4? Promptbases benchmarking säger annorlunda
Head-to-head tester visar att GPT-4 Turbo kanter ut Claude 3 i alla kategorier.
![]() 2 min. läsa
2 min. läsa
![]() Publicerad den
Publicerad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Viktiga anteckningar
- Anthropic lanserade nyligen Claude 3, utsedd för att överträffa GPT-4 och Google Gemini 1.0 Ultra.
- Postade benchmarkpoäng visar att Claude 3 Opus utmärker sig på olika områden jämfört med sina motsvarigheter.
- Ytterligare analys tyder dock på att GPT-4 Turbo överträffar Claude 3 i direkta jämförelser, vilket innebär potentiella fördomar i rapporterade resultat.

Anthropic har precis lanserade Claude 3 för inte så länge sedan, dess AI-modell som sägs kunna slå OpenAI:s GPT-4 och Google Gemini 1.0 Ultra. Den kommer med tre varianter: Claude 3 Haiku, Sonnet och Opus, alla för olika användningsområden.
I sitt första tillkännagivande, säger AI-företaget att Claude 3 är något överlägsen dessa två nyligen lanserade modeller.
Enligt de publicerade benchmarkpoängen är Claude 3 Opus bättre i kunskaper på grundnivå (MMLU), resonemang på forskarnivå (GPQA), matematik och matematisk problemlösning i grundskolan, flerspråkig matematik, kodning, resonemang över text och andra mer än GPT-4 och Gemini 1.0 Ultra och Pro.
Men det målar inte helt upp hela bilden sanningsenligt. Den postade benchmark-poängen på tillkännagivandet (särskilt för GPT-4) togs tydligen från GPT-4 på releaseversionen från mars 2023 förra året (krediter till AI-entusiasten @TolgaBilge_ på X)
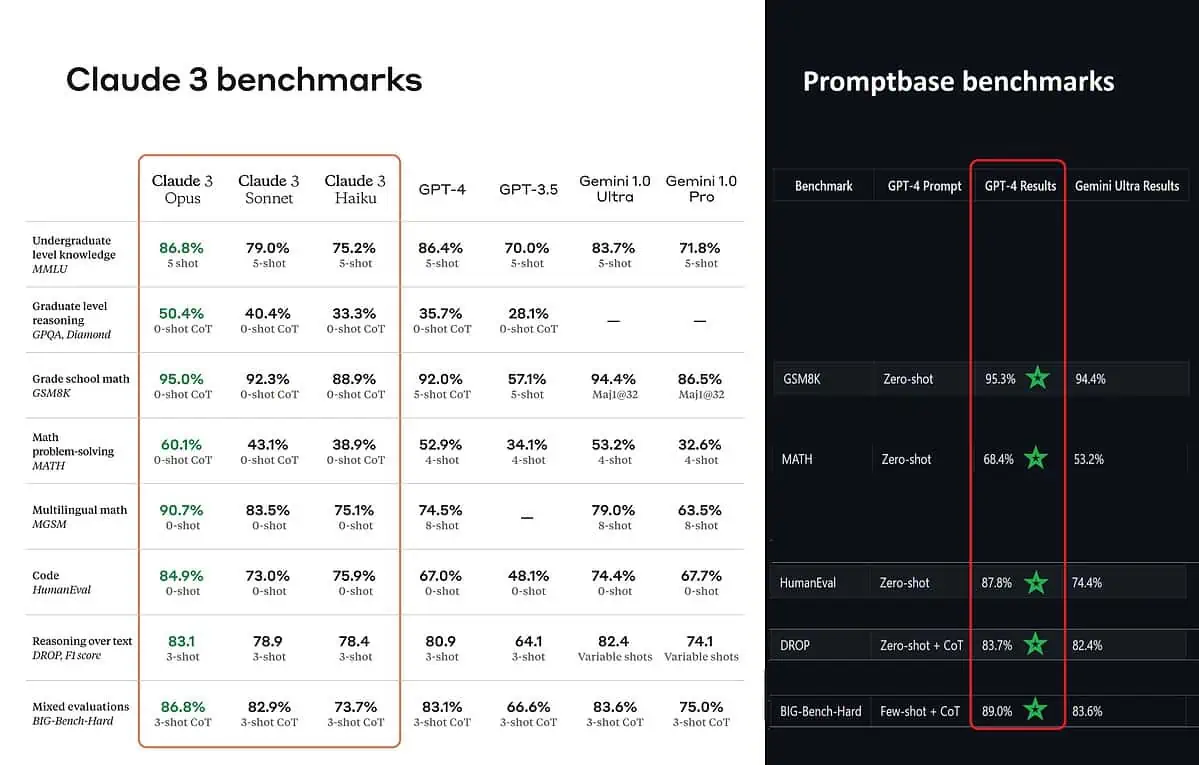
Ett verktyg som analyserar prestanda (benchmark analyzer) kallas Promptbas visar att GPT-4 Turbo faktiskt slog Claude 3 i alla tester de direkt kunde jämföra dem på. Dessa test täcker saker som grundläggande matematiska färdigheter (GSM8K & MATH), skriva kod (HumanEval), resonemang över text (DROP) och en blandning av andra utmaningar.
Samtidigt som de tillkännager sina resultat, Anthropic också nämner i en fotnot att deras ingenjörer kunde förbättra GPT-4T:s prestanda ytterligare genom att finjustera den specifikt för testerna. Detta tyder på att de rapporterade resultaten kanske inte återspeglar basmodellens verkliga kapacitet.
Aj.