Generátor prevodu textu na obrázok spoločnosti Google Imagen vytvára obrázky s „bezprecedentným stupňom fotorealizmu“
![]() 3 min. čítať
3 min. čítať
![]() Publikované dňa
Publikované dňa
Zdieľajte tento článok

Vylepšite túto príručku
Prečítajte si našu informačnú stránku a zistite, ako môžete pomôcť MSPoweruser udržať redakčný tím Čítaj viac
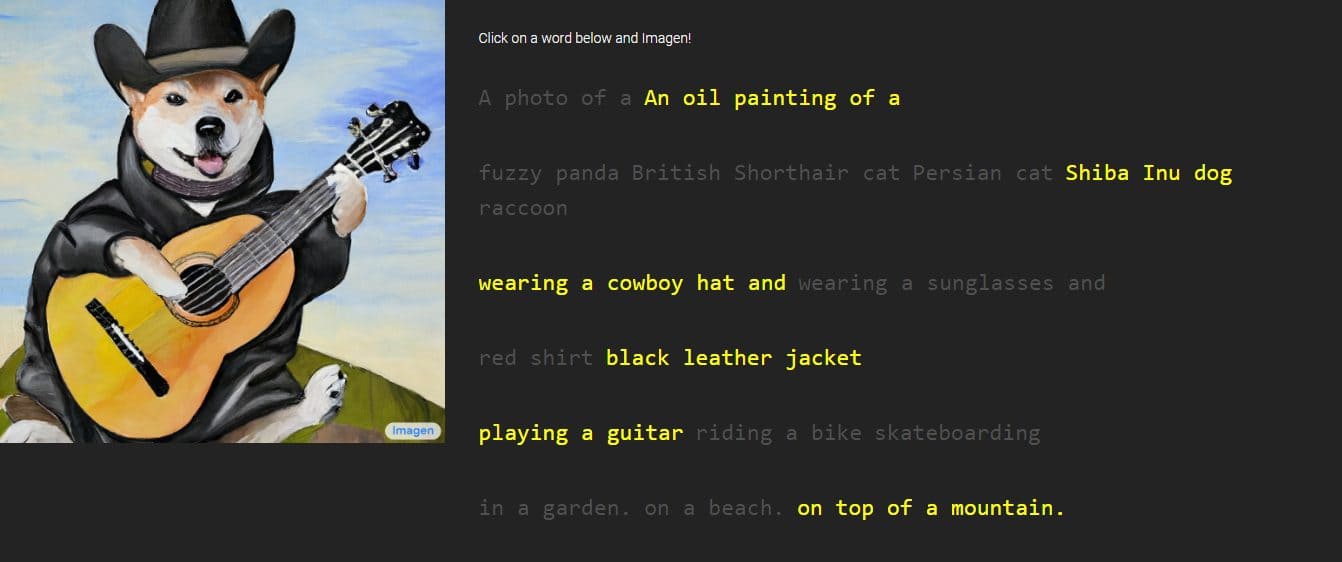
Google odhalil nový výtvor s názvom „Obraz,“ generátor textu na obrázok prostredníctvom popisov, ktoré osoba poskytne. Spoločnosť tvrdí, že výkonom prevyšuje DALL-E 2, ďalší generátor obrazu AI. Predstavil niekoľko vzoriek, ktoré nepopierateľne vykazujú vynikajúce detaily, ale Imagen je v súčasnosti pre verejnosť nedostupný.
O novom modeli šírenia textu na obrázok sa hovorí, že má „bezprecedentný stupeň fotorealizmu a hlbokú úroveň jazykového porozumenia“. Rozumie textu prostredníctvom veľkých modelov jazyka transformátora a hovorí sa, že pri vytváraní obrazu s vysokou vernosťou sa spolieha na difúzne modely.

Google poskytol obrázky a ukážky Imagenovej práce so štýlmi od kresieb po olejomaľby a CGI. Sú sprevádzané slovami a frázami použitými na ich vytvorenie. Napríklad jedna vzorka znie: „dračie ovocie s pásom karate v snehu“, zatiaľ čo druhá má popis „malý kaktus so slameným klobúkom a neónovými slnečnými okuliarmi na saharskej púšti“.
Vygenerované obrázky vyzerajú neuveriteľne reálne, ako keby ich vytvorila skutočná osoba. Google však hovorí, že sa to robí prostredníctvom difúznych technológií využívaním čistého šumového obrazu a jeho vylepšovaním najlepším možným spôsobom. Po pochopení poskytnutého textového popisu Imagen vygeneruje obrázok s rozmermi 64 x 64 pixelov, vykoná dve vylepšenia a skonvertuje obrázok na väčší kus s rozlíšením 1024 x 1024 pixelov.
Google Research, Brain Team hovorí, že Imagen exceloval COCO (rozsiahly súbor údajov na detekciu objektov, segmentáciu a popisovanie) napriek tomu, že na to nie ste vyškolení. Tím oznámil, že získal nové, najmodernejšie skóre FID 7.27.
Google tiež porovnal výkon Imagen s inými modelmi prevodu textu na obrázok tak, že ich posúdil pomocou funkcie „DrawBench“. Slúži ako benchmark pre modely text-to-image, kde Google testoval Imagen s inými metódami, ako sú VQ-GAN+CLIP, Latent Diffusion Models a DALL-E 2. Po testovaní ich zloženia, mohutnosti, priestorových vzťahov, dlhého tvaru text, vzácne slová a náročné výzvy, tím povedal, že „ľudskí hodnotitelia silne uprednostňujú Imagen pred inými metódami, a to ako v zarovnaní obrazu a textu, tak aj vo vernosti obrazu“.
Napriek týmto pôsobivým správam od výskumného tímu, testovanie Imagen sami nebude možné, pretože nie je prístupné verejnosti. Google má na to dôvody, ako sú etické výzvy, potenciálne riziká zneužitia, sociálne predsudky, obmedzenia veľkých jazykových modelov a riziko zakódovaných škodlivých stereotypov a reprezentácií. Tím zhrnul, že so všetkými týmito výzvami Imagen stále nie je dokonalý, pokiaľ ide o generovanie obrázkov súvisiacich s ľuďmi.
„Imagen vykazuje vážne obmedzenia pri vytváraní obrázkov zobrazujúcich ľudí,“ vysvetľuje tím v blogovom príspevku. „Naše ľudské hodnotenia zistili, že Imagen získava výrazne vyššie preferencie, keď sa hodnotí na obrázkoch, ktoré nezobrazujú ľudí, čo naznačuje zhoršenie vernosti obrazu. Predbežné hodnotenie tiež naznačuje, že Imagen kóduje niekoľko spoločenských predsudkov a stereotypov, vrátane celkovej zaujatosti smerom k vytváraniu obrázkov ľudí so svetlejším odtieňom pleti a tendencie, aby sa obrázky zobrazujúce rôzne profesie zhodovali so západnými rodovými stereotypmi. Nakoniec, aj keď sa sústredíme na generácie od ľudí, naša predbežná analýza naznačuje, že Imagen pri vytváraní obrazov aktivít, udalostí a predmetov kóduje celý rad sociálnych a kultúrnych predsudkov. Naším cieľom je dosiahnuť pokrok v niekoľkých z týchto otvorených výziev a obmedzení v budúcej práci.“