Генератор Google Imagen для преобразования текста в изображения создает изображения с «беспрецедентной степенью фотореализма».
![]() 3 минута. читать
3 минута. читать
![]() Опубликовано
Опубликовано
Поделиться этой статьей

Улучшите это руководство
Прочтите нашу страницу раскрытия информации, чтобы узнать, как вы можете помочь MSPoweruser поддержать редакционную команду. Читать далее
Google представил новое творение под названием «Изображение», генератор текста в изображение с помощью описаний, которые предоставит человек. Компания утверждает, что она превосходит по производительности DALL-E 2, еще один генератор изображений с искусственным интеллектом. В нем представлены некоторые образцы, которые, несомненно, демонстрируют изысканные детали, но Imagen в настоящее время недоступен для публики.
Новая модель преобразования текста в изображение характеризуется «беспрецедентной степенью фотореализма и глубоким пониманием языка». Он понимает текст с помощью больших языковых моделей преобразования и, как говорят, полагается на модели распространения для выполнения высокоточной генерации изображений.

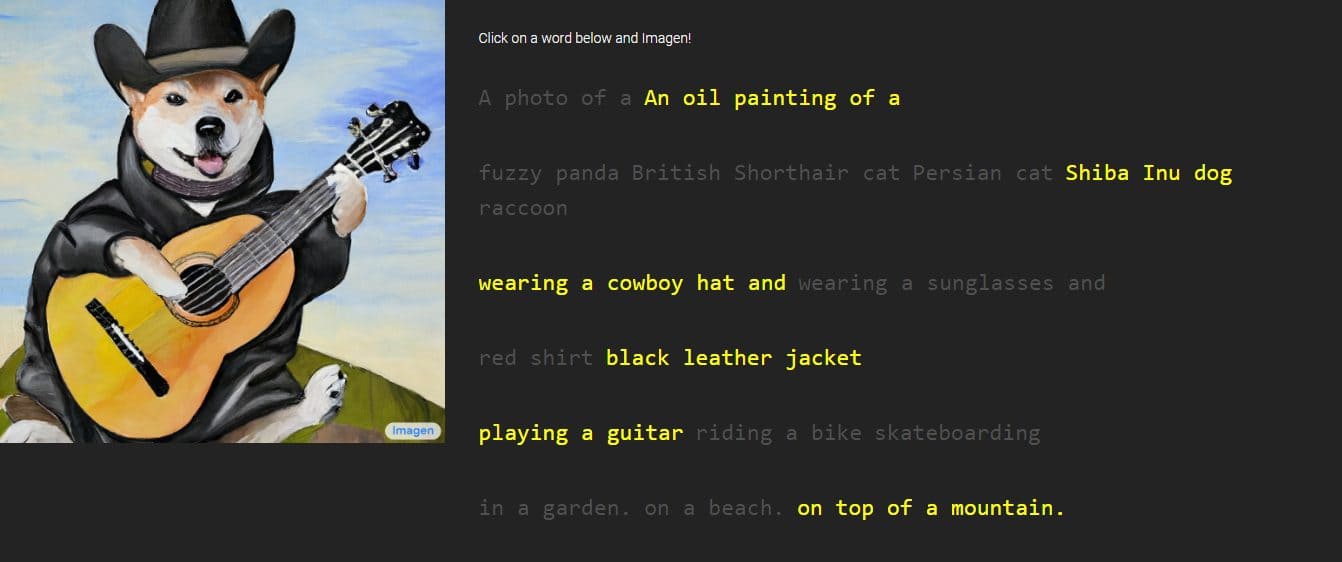
Google предоставил изображения и образцы работ Imagen, стили которых варьируются от рисунков до картин маслом и компьютерной графики. Они сопровождаются словами и фразами, используемыми для их создания. Например, в одном образце написано «драконий фрукт в поясе для карате в снегу», а в другом — «небольшой кактус в соломенной шляпе и неоновых солнцезащитных очках в пустыне Сахара».
Сгенерированные изображения выглядят невероятно реальными, как будто они были созданы реальным человеком. Тем не менее, Google говорит, что это делается с помощью технологий распространения, используя изображение чистого шума и улучшая его наилучшим образом. Поняв предоставленное текстовое описание, Imagen сгенерирует изображение размером 64 x 64 пикселя, выполнит два улучшения и преобразует изображение в более крупный фрагмент размером 1024 x 1024 пикселя.
Google Research, Brain Team говорит, что Imagen преуспел в Кокос (крупномасштабный набор данных для обнаружения, сегментации и подписи объектов), несмотря на то, что он не обучен этому. Команда сообщила, что получила новую современную оценку FID 7.27.
Google также сравнил производительность Imagen с другими моделями преобразования текста в изображение, оценив их с помощью «DrawBench». Он служит эталоном для моделей преобразования текста в изображение, где Google тестировал Imagen с другими методами, такими как VQ-GAN+CLIP, модели скрытой диффузии и DALL-E 2. После тестирования их композиционности, мощности, пространственных отношений, длинных форм текст, редкие слова и сложные подсказки, команда сказала, что «оценщики-люди решительно предпочитают Imagen другим методам как в выравнивании изображения-текста, так и в точности изображения».
Несмотря на эти впечатляющие отчеты исследовательской группы, протестировать Imagen самостоятельно будет невозможно, поскольку он недоступен для общественности. У Google есть причины для этого, такие как этические проблемы, потенциальные риски неправильного использования, социальные предубеждения, ограничения больших языковых моделей и риск закодированных вредных стереотипов и представлений. Команда резюмирует, что со всеми этими проблемами Imagen все еще не идеален, когда дело доходит до создания изображений, связанных с людьми.
«Imagen демонстрирует серьезные ограничения при создании изображений, изображающих людей», — объясняет команда в своем блоге. «Наши оценки на людях показали, что Imagen получает значительно более высокие показатели предпочтения при оценке изображений, на которых не изображены люди, что указывает на ухудшение точности изображения. Предварительная оценка также предполагает, что Imagen кодирует несколько социальных предубеждений и стереотипов, в том числе общую предвзятость к созданию изображений людей с более светлым оттенком кожи и тенденцию к тому, чтобы изображения, изображающие разные профессии, соответствовали западным гендерным стереотипам. Наконец, даже когда мы фокусируем внимание на поколениях людей, наш предварительный анализ показывает, что Imagen кодирует ряд социальных и культурных предубеждений при создании изображений действий, событий и объектов. Мы стремимся добиться прогресса в решении некоторых из этих открытых проблем и ограничений в будущей работе».