Microsoft demonstrează că GPT-4 poate învinge Google Gemini Ultra folosind noi tehnici de promptare
![]() 2 min. citit
2 min. citit
![]() Publicat în data de
Publicat în data de
Distribuiți acest articol

Îmbunătățiți acest ghid
Citiți pagina noastră de dezvăluire pentru a afla cum puteți ajuta MSPoweruser să susțină echipa editorială Află mai multe
Săptămâna trecută, Google a anunțat zodia Gemeni, modelul său cel mai capabil și general de până acum. Modelul Google Gemini oferă performanțe de ultimă generație în cadrul multor benchmark-uri de top. Google a evidențiat că performanța celui mai capabil model Gemini Ultra depășește rezultatele OpenAI GPT-4 la 30 din cele 32 de repere academice utilizate pe scară largă în cercetarea și dezvoltarea modelului de limbaj mari (LLM).
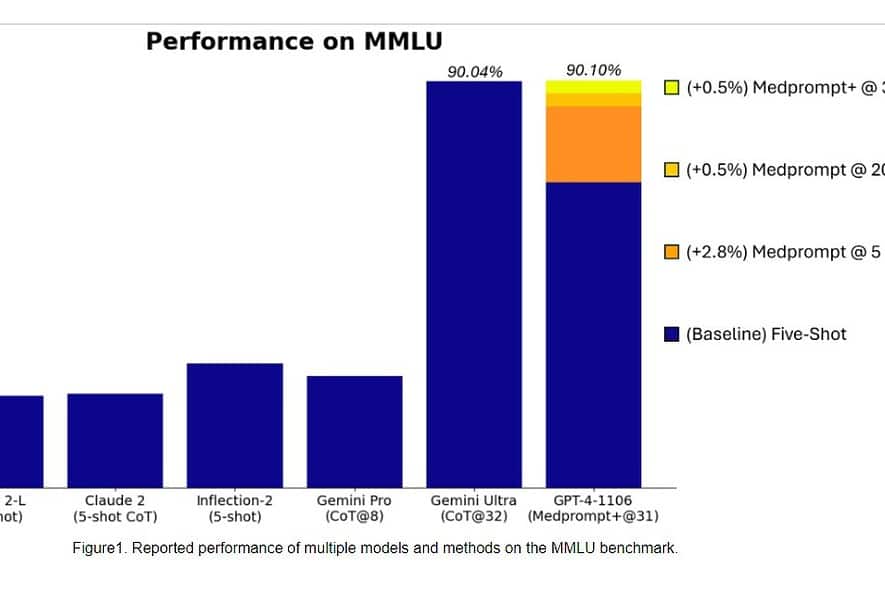
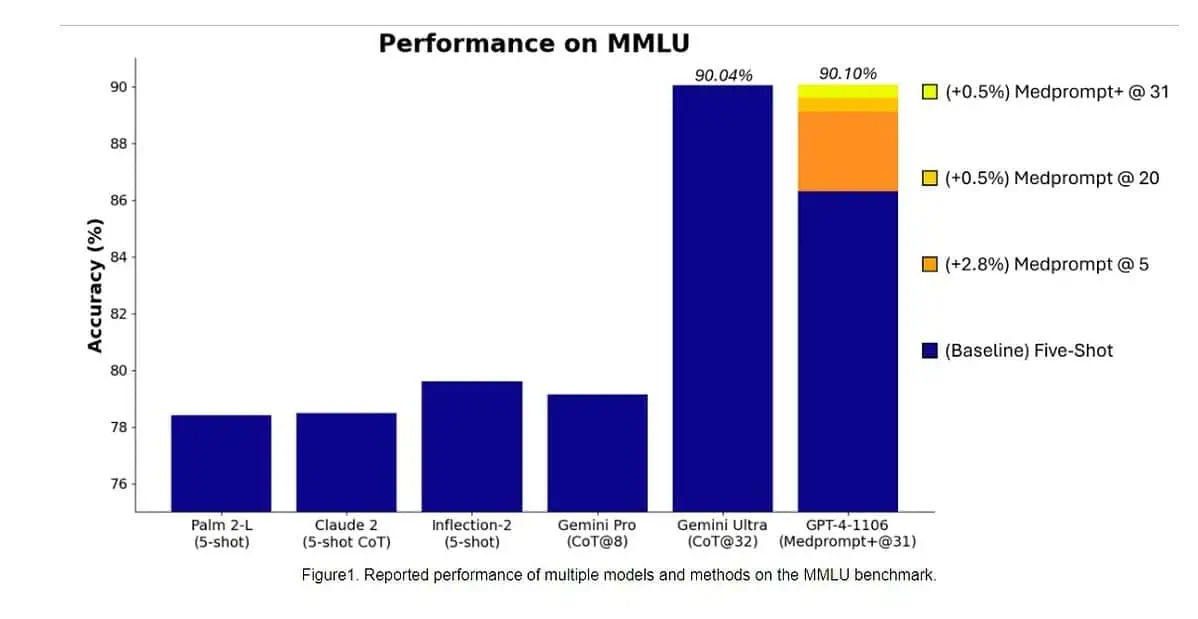
Mai exact, Gemini Ultra a devenit primul model care a depășit experții umani în ceea ce privește MMLU (înțelegerea masivă a limbajului multitask) cu un scor de 90%, care utilizează o combinație de 57 de materii precum matematică, fizică, istorie, drept, medicină și etică pentru testarea atât a cunoștințelor lumii. și abilități de rezolvare a problemelor.
Ieri, echipa de cercetare Microsoft dezvăluit că modelul GPT-4 al OpenAI poate învinge Google Gemini Ultra atunci când sunt folosite noi tehnici de solicitare. Luna trecută, a dezvăluit Microsoft Research Medprompt, o compoziție de mai multe strategii de stimulare care îmbunătățește considerabil performanța GPT-4 și realizează rezultate de ultimă generație în suita MultiMedQA. Microsoft a aplicat acum tehnicile de promptare utilizate în Medprompt și pentru domeniile generale. Potrivit Microsoft, modelul OpenAI GPT-4 atunci când este utilizat cu o versiune modificată a Medprompt atinge cel mai mare scor obținut vreodată pe MMLU complet. Da, OpenAI GPT-4 poate învinge viitorul model Gemini Ultra doar folosind tehnicile de promptare. Acest lucru arată că nu am atins încă potențialul maxim al modelelor deja lansate precum GPT-4.
Aruncă o privire la comparația de referință între modelele GPT-4 (prompții îmbunătățite) și Gemini Ultra de mai jos.
| Benchmark | GPT-4 Prompt | Rezultate GPT-4 | Rezultate Gemini Ultra |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.27% | 94.4% |
| MATH | Zero-shot | 68.42% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bancă-Hard | Câțiva injecții + CoT* | 89.0% | 83.6% |
| CĂDERE BRUSCA | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10 lovituri** | 95.3% | 87.8% |
În primul rând, Microsoft a aplicat Medprompt original la GPT-4 pentru a obține scorul de 89.1% în MMLU. Ulterior, Microsoft a crescut numărul de apeluri ansamblu în Medprompt de la cinci la 20, ceea ce a condus la un scor sporit de 89.56%. Ulterior, Microsoft a extins Medprompt la Medprompt+ prin adăugarea unei metode de promptare mai simplă și prin formularea unei politici pentru obținerea unui răspuns final prin integrarea rezultatelor atât din strategia de bază Medprompt, cât și din prompturile simple. Acest lucru a condus GPT-4 să atingă un scor record de 90.10%. Echipa Microsoft Research a menționat că echipa Google Gemini folosea, de asemenea, o tehnică similară de solicitare pentru a obține scorurile record pe MMLU.
Puteți afla mai multe despre tehnicile de solicitare folosite de Microsoft pentru a învinge Gemini Ultra aici.