Claude 3 este într-adevăr mai bun decât GPT-4? Benchmarking-ul lui Promptbase spune altceva
Testele directe arată că GPT-4 Turbo îl devansează pe Claude 3 în toate categoriile.
![]() 2 min. citit
2 min. citit
![]() Actualizat pe
Actualizat pe
Distribuiți acest articol

Îmbunătățiți acest ghid
Citiți pagina noastră de dezvăluire pentru a afla cum puteți ajuta MSPoweruser să susțină echipa editorială Afla mai multe
Note cheie
- Anthropic a lansat recent Claude 3, promovat pentru a depăși GPT-4 și Google Gemini 1.0 Ultra.
- Scorurile de referință postate indică că Claude 3 Opus excelează în diferite domenii în comparație cu omologii săi.
- Cu toate acestea, analize suplimentare sugerează că GPT-4 Turbo îl depășește pe Claude 3 în comparații directe, ceea ce implică potențiale părtiniri în rezultatele raportate.

Antropic are tocmai a lansat Claude 3 nu cu mult timp în urmă, modelul său AI despre care se spune că poate depăși OpenAI GPT-4 și Google Gemini 1.0 Ultra. Vine cu trei variante: Claude 3 Haiku, Sonnet și Opus, toate pentru diferite utilizări.
În cadrul anuntul initial, compania AI spune că Claude 3 este ușor superior acestor două modele lansate recent.
Conform scorurilor de referință postate, Claude 3 Opus este mai bun în cunoștințe la nivel de licență (MMLU), raționament la nivel de absolvent (GPQA), matematică și rezolvare de probleme de matematică pentru școala generală, matematică multilingvă, codificare, raționament asupra textului și altele. decât GPT-4 și Gemini 1.0 Ultra și Pro.
Cu toate acestea, asta nu pictează în întregime întreaga imagine în mod adevărat. Scorul de referință postat pe anunț (în special pentru GPT-4) a fost aparent preluat din GPT-4 în versiunea de lansare din martie 2023 anul trecut (credite pasionatului de AI @TolgaBilge_ pe X)
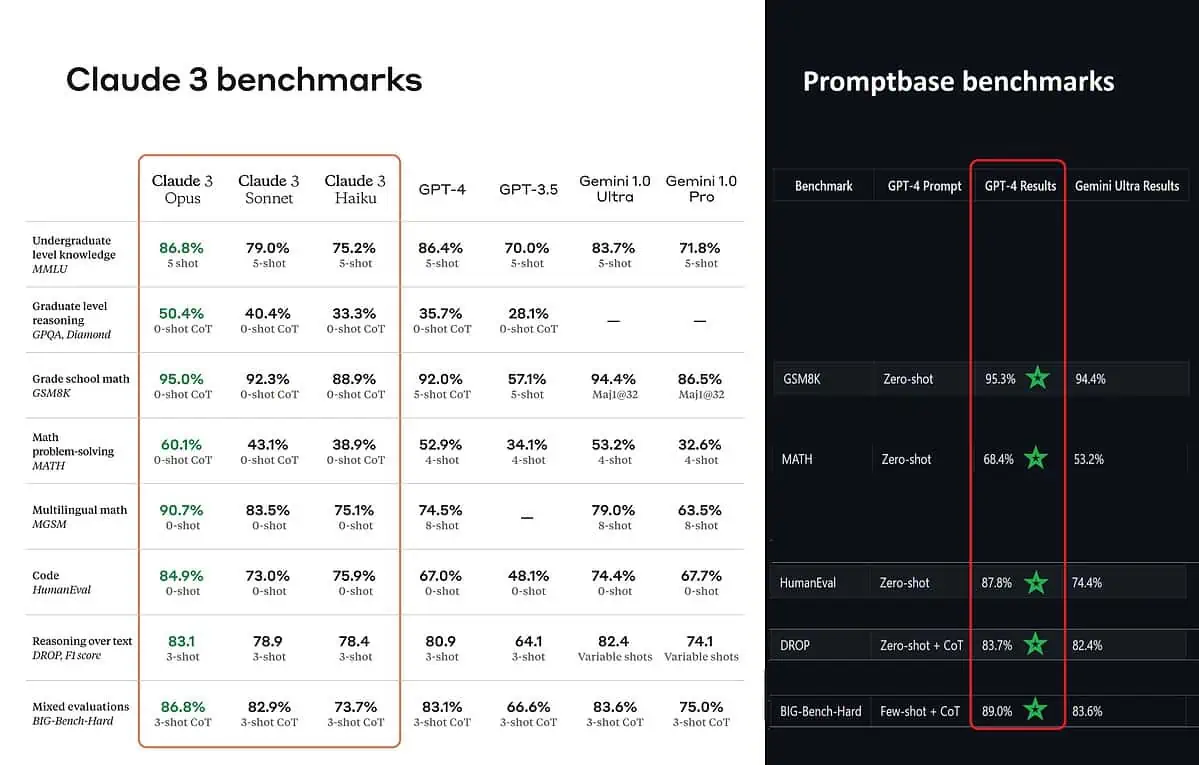
Un instrument care analizează performanța (analizator de referință) numit Promptbase arată că GPT-4 Turbo chiar l-a învins pe Claude 3 în toate testele pe care le-ar putea compara direct. Aceste teste acoperă lucruri precum abilitățile de bază de matematică (GSM8K și MATH), scrierea codului (HumanEval), raționamentul asupra textului (DROP) și o combinație de alte provocări.
În timp ce își anunță rezultatele, Anthropic și el mențiuni într-o notă de subsol că inginerii lor au reușit să îmbunătățească performanța GPT-4T în continuare, ajustându-l special pentru teste. Acest lucru sugerează că rezultatele raportate ar putea să nu reflecte adevăratele capacități ale modelului de bază.
Ouch.





Forumul utilizatorilor
0 mesaje