Generatorul Google text-to-image, Imagen produce imagini cu „grad fără precedent de fotorealism”
![]() 3 min. citit
3 min. citit
![]() Publicat în data de
Publicat în data de
Distribuiți acest articol

Îmbunătățiți acest ghid
Citiți pagina noastră de dezvăluire pentru a afla cum puteți ajuta MSPoweruser să susțină echipa editorială Află mai multe
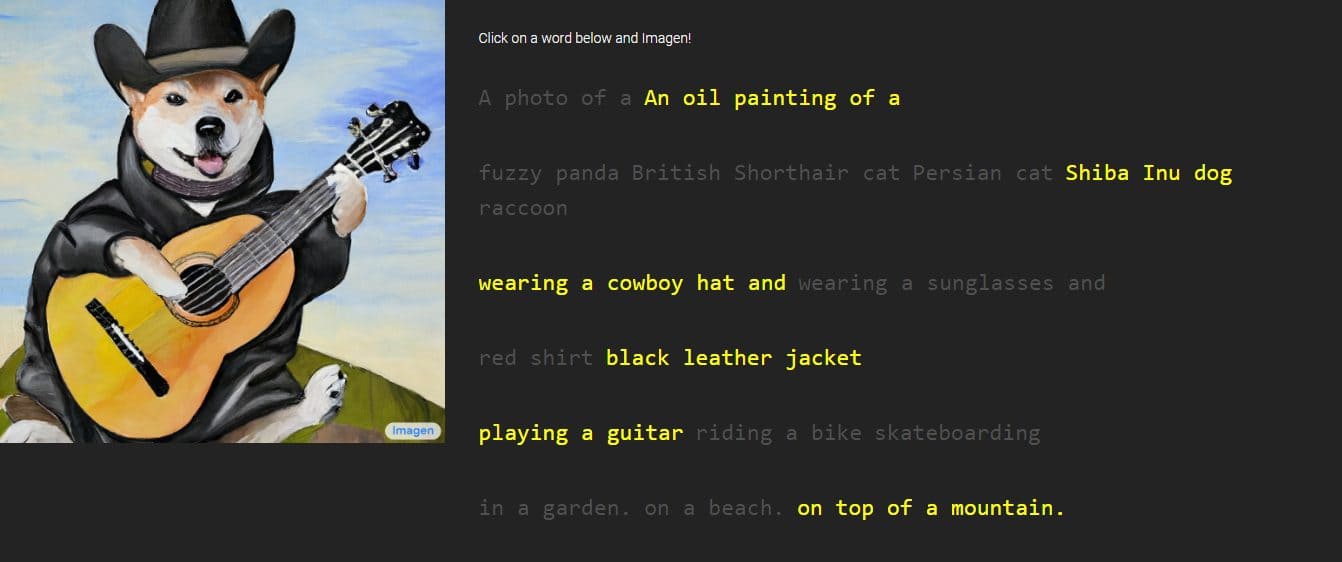
Google a dezvăluit o nouă creație numită „Imagine”, un generator de text în imagine prin descrierile pe care o persoană le va oferi. Compania susține că depășește performanța DALL-E 2, un alt generator de imagini AI. A prezentat câteva mostre, care indică incontestabil detalii rafinate, dar Imagen este momentan indisponibilă publicului.
Noul model de difuzare text-to-image este descris ca având „un grad fără precedent de fotorealism și un nivel profund de înțelegere a limbajului”. Înțelege textul prin modele mari de limbaj transformator și se spune că se bazează pe modele de difuzie pentru a genera imagini de înaltă fidelitate.

Google a oferit imagini și mostre ale lucrării lui Imagen, cu stiluri variind de la desene la picturi în ulei și CGI. Ele sunt însoțite de cuvintele și expresiile folosite pentru a le genera. De exemplu, un eșantion spune „un fruct dragon care poartă centura de karate în zăpadă”, în timp ce celălalt are descrierea „un mic cactus purtând o pălărie de paie și ochelari de soare neon în deșertul Sahara”.
Imaginile generate arată incredibil de reale ca și cum ar fi fost create de o persoană reală. Cu toate acestea, Google spune că se realizează prin tehnologii de difuzie prin utilizarea unei imagini cu zgomot pur și rafinarea acesteia în cel mai bun mod posibil. Înțelegând descrierea textului furnizat, Imagen va genera o imagine de 64 x 64 pixeli, va efectua două îmbunătățiri și va converti imaginea într-o bucată mai mare de 1024 x 1024 pixeli.
Google Research, Brain Team spune că Imagen a excelat NUCĂ DE COCOS (un set de date de detectare a obiectelor, segmentare și subtitrări la scară largă) în ciuda faptului că nu a fost instruit în acest sens. Echipa a raportat că a primit un nou scor FID de 7.27.
De asemenea, Google a comparat performanța Imagen cu alte modele text-to-image, evaluându-le folosind „DrawBench”. Acesta servește drept etalon pentru modelele text-to-image în care Google a testat Imagen cu alte metode precum VQ-GAN+CLIP, Modele de difuzie latentă și DALL-E 2. După testarea compoziționalității, cardinalității, relațiilor spațiale, forma lungă. text, cuvinte rare și sugestii provocatoare, echipa a spus că „evaluatorii umani preferă cu multă imagine în locul altor metode, atât în ceea ce privește alinierea imagine-text, cât și fidelitatea imaginii”.
În ciuda acestor rapoarte impresionante din partea echipei de cercetare, testarea dvs. Imagen nu va fi posibilă, deoarece nu este accesibilă publicului. Google are motive pentru asta, cum ar fi provocări etice, riscuri potențiale de utilizare abuzivă, părtiniri sociale, limitări ale modelelor de limbaj mari și riscul de stereotipuri și reprezentări dăunătoare codificate. Echipa rezumă că, cu toate aceste provocări, Imagen încă nu este perfectă când vine vorba de generarea de imagini legate de oameni.
„Imagen prezintă limitări serioase atunci când generează imagini care înfățișează oameni”, explică echipa într-o postare pe blog. „Evaluările noastre umane au descoperit că Imagen obține rate de preferință semnificativ mai mari atunci când este evaluată pe imagini care nu prezintă oameni, indicând o degradare a fidelității imaginii. Evaluarea preliminară sugerează, de asemenea, că Imagen codifică mai multe prejudecăți și stereotipuri sociale, inclusiv o prejudecată generală către generarea de imagini cu persoane cu nuanțe mai deschise ale pielii și o tendință ca imaginile care prezintă diferite profesii să se alinieze cu stereotipurile de gen occidentale. În cele din urmă, chiar și atunci când concentrăm generații departe de oameni, analiza noastră preliminară indică că Imagen codifică o serie de prejudecăți sociale și culturale atunci când generează imagini cu activități, evenimente și obiecte. Ne propunem să facem progrese cu privire la câteva dintre aceste provocări și limitări deschise în lucrările viitoare.”