Microsoft apresenta família de modelos Phi-3 que superam outros modelos de sua classe
![]() 2 minutos. ler
2 minutos. ler
![]() Publicado em
Publicado em
Compartilhe este artigo

Melhore este guia
Leia nossa página de divulgação para descobrir como você pode ajudar o MSPoweruser a sustentar a equipe editorial Saiba mais
Em dezembro de 2023, a Microsoft lançou Phi-2 modelo com 2.7 bilhões de parâmetros que proporcionou desempenho de última geração entre modelos de linguagem base com menos de 13 bilhões de parâmetros. Nos últimos quatro meses, vários outros modelos lançados superaram o Phi-2. Recentemente, a Meta lançou a família de modelos Llama-3 que superou todos os modelos de código aberto lançados anteriormente.
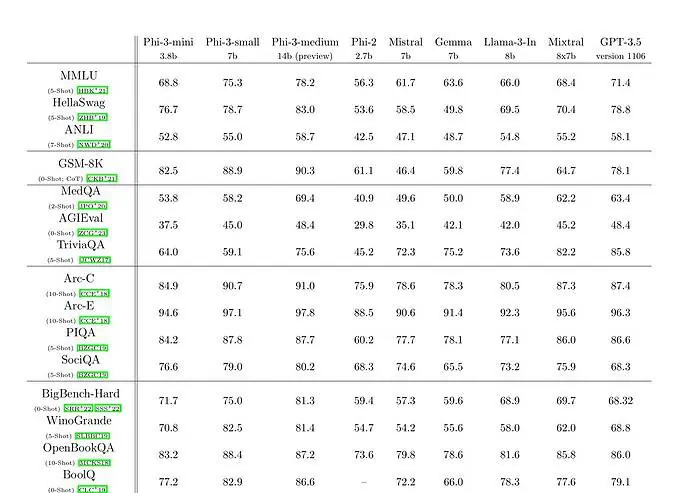
Ontem à noite, a Microsoft Research anunciou a família de modelos Phi-3 via um relatório técnico. Existem três modelos na família Phi-3:
- phi-3-mini (3.8B)
- phi-3-pequeno (7B)
- phi-3-médio (14B)
O phi-3-mini com um modelo de linguagem de 3.8 bilhões de parâmetros é treinado em 3.3 trilhões de tokens. De acordo com benchmarks, o phi-3-mini supera Mixtral 8x7B e GPT-3.5. A Microsoft afirma que este modelo é pequeno o suficiente para ser implantado em um telefone. A Microsoft usou uma versão ampliada do conjunto de dados usado para phi-2, composto de dados da web altamente filtrados e dados sintéticos. De acordo com os resultados de benchmark da Microsoft no documento técnico, phi-3-small e phi-3-medium alcançam uma pontuação MMLU impressionante de 75.3 e 78.2, respectivamente.
Em termos de capacidades LLM, embora o modelo Phi-3-mini atinja um nível semelhante de compreensão da linguagem e capacidade de raciocínio aos de modelos muito maiores, ainda é fundamentalmente limitado pelo seu tamanho para determinadas tarefas. O modelo simplesmente não tem capacidade de armazenar amplo conhecimento factual, o que pode ser observado, por exemplo, no baixo desempenho do TriviaQA. No entanto, acreditamos que esta fraqueza pode ser resolvida através do aumento com um motor de busca.