Claude 3 é realmente melhor que GPT-4? O benchmarking do Promptbase diz diferente
Testes frente a frente mostram que o GPT-4 Turbo supera Claude 3 em todas as categorias.
![]() 2 minutos. ler
2 minutos. ler
![]() Atualizado em
Atualizado em
Compartilhe este artigo

Melhore este guia
Leia nossa página de divulgação para descobrir como você pode ajudar o MSPoweruser a sustentar a equipe editorial Saiba mais
Notas chave
- A Anthropic lançou recentemente o Claude 3, que supera o GPT-4 e o Google Gemini 1.0 Ultra.
- As pontuações de benchmark publicadas indicam que Claude 3 Opus se destaca em diversas áreas em comparação com seus equivalentes.
- No entanto, análises mais aprofundadas sugerem que o GPT-4 Turbo supera o Claude 3 em comparações diretas, implicando potenciais vieses nos resultados relatados.

A Antrópico acaba de lançou Cláudio 3 não muito tempo atrás, seu modelo de IA seria capaz de vencer o GPT-4 da OpenAI e o Google Gemini 1.0 Ultra. Ele vem com três variantes: Claude 3 Haiku, Sonnet e Opus, todas para usos diferentes.
Na sua anúncio inicial, a empresa de IA afirma que o Claude 3 é ligeiramente superior a estes dois modelos lançados recentemente.
De acordo com as pontuações de referência publicadas, Claude 3 Opus é melhor em conhecimento de nível de graduação (MMLU), raciocínio de pós-graduação (GPQA), matemática do ensino fundamental e resolução de problemas de matemática, matemática multilíngue, codificação, raciocínio sobre texto e outros mais do que GPT-4 e Gemini 1.0 Ultra e Pro.
No entanto, isso não pinta todo o quadro com sinceridade. A pontuação de benchmark publicada no anúncio (especialmente para GPT-4) foi aparentemente retirada do GPT-4 na versão de lançamento de março de 2023 do ano passado (créditos aos entusiastas de IA @TolgaBilge_ no X)
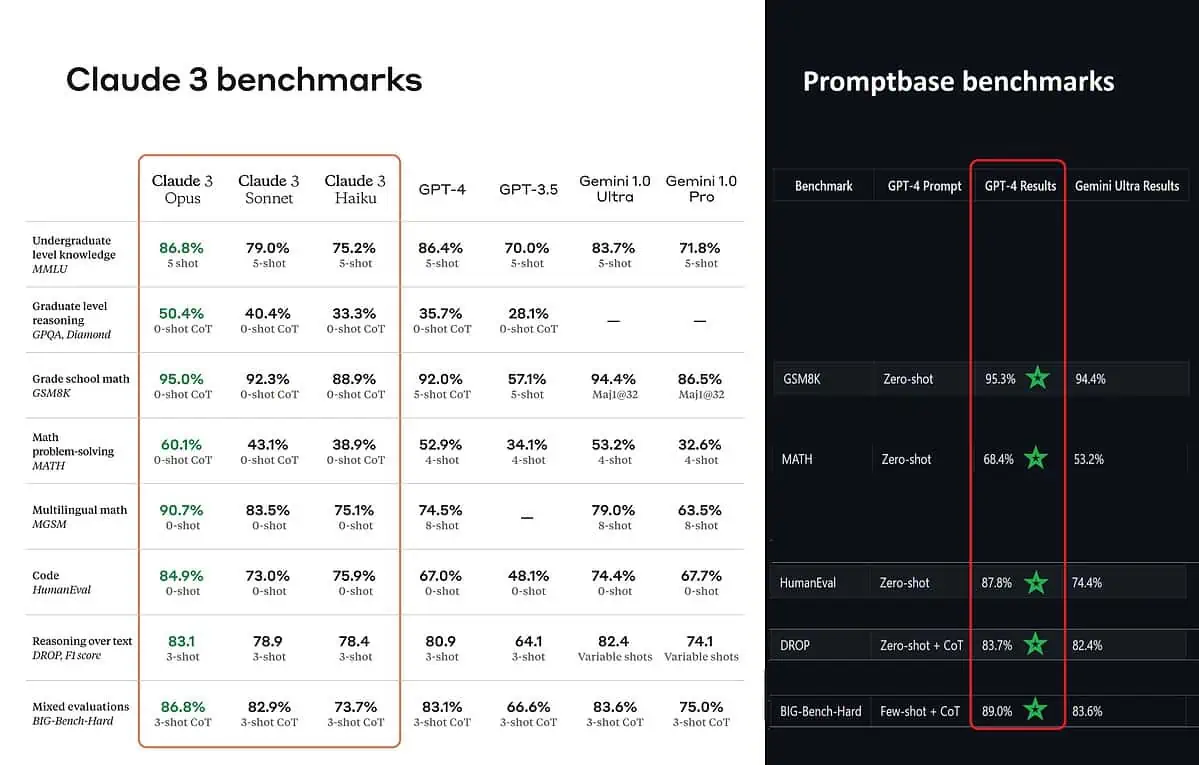
Uma ferramenta que analisa desempenho (analisador de benchmark) chamada Base de prompt mostra que o GPT-4 Turbo realmente venceu Claude 3 em todos os testes em que puderam compará-los diretamente. Esses testes abrangem habilidades matemáticas básicas (GSM8K e MATH), escrita de código (HumanEval), raciocínio sobre texto (DROP) e uma combinação de outros desafios.
Ao anunciar seus resultados, a Anthropic também menciona em uma nota de rodapé que seus engenheiros foram capazes de melhorar ainda mais o desempenho do GPT-4T, ajustando-o especificamente para os testes. Isto sugere que os resultados relatados podem não refletir as verdadeiras capacidades do modelo base.
Ouch.





Fórum de usuários
Mensagens 0