O gerador de texto para imagem do Google, Imagen, produz imagens com 'grau de fotorrealismo sem precedentes'
![]() 3 minutos. ler
3 minutos. ler
![]() Publicado em
Publicado em
Compartilhe este artigo

Melhore este guia
Leia nossa página de divulgação para descobrir como você pode ajudar o MSPoweruser a sustentar a equipe editorial Saiba mais
Google revelou uma nova criação chamada “Imagem”, um gerador de texto para imagem por meio de descrições que uma pessoa fornecerá. A empresa afirma que supera o desempenho do DALL-E 2, outro gerador de imagens de IA. Apresentou algumas amostras, que inegavelmente mostram detalhes requintados, mas o Imagen está atualmente indisponível ao público.
O novo modelo de difusão de texto para imagem é descrito como tendo “um grau sem precedentes de fotorrealismo e um nível profundo de compreensão da linguagem”. Ele entende texto por meio de grandes modelos de linguagem de transformador e diz-se que depende de modelos de difusão para realizar a geração de imagens de alta fidelidade.

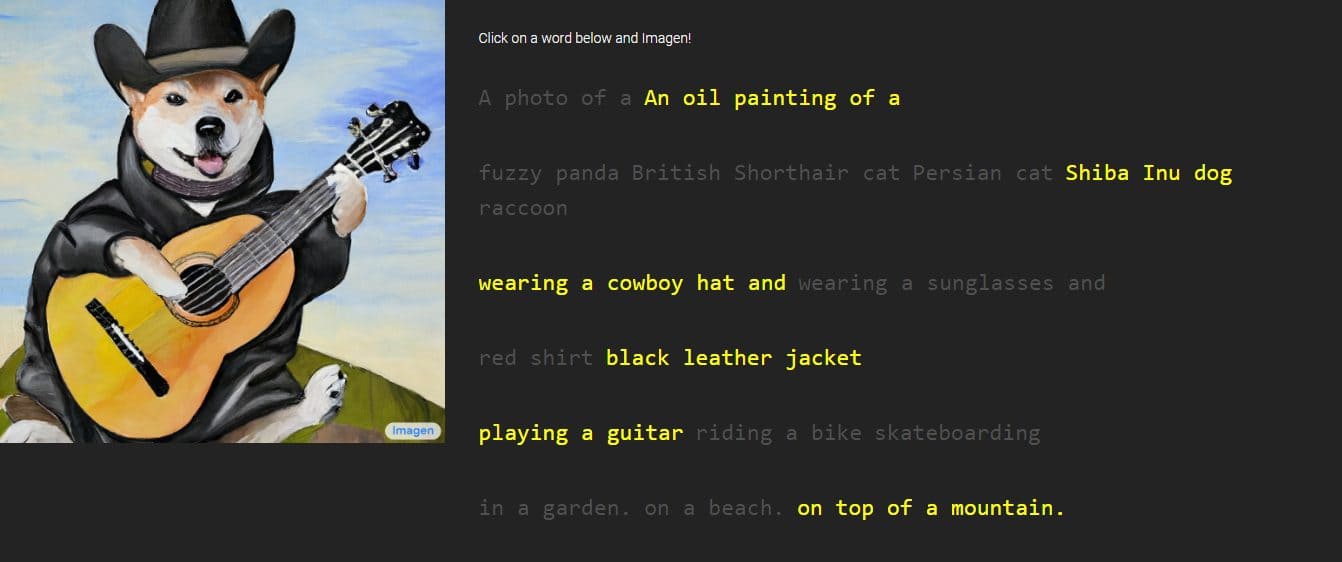
O Google forneceu imagens e amostras do trabalho de Imagen, com estilos variando de desenhos a pinturas a óleo e CGIs. Eles são acompanhados pelas palavras e frases usadas para gerá-los. Por exemplo, uma amostra diz: “uma fruta do dragão usando cinto de karatê na neve”, enquanto a outra tem a descrição “um pequeno cacto usando um chapéu de palha e óculos de sol de néon no deserto do Saara”.
As imagens geradas parecem incrivelmente reais como se fossem criadas por uma pessoa real. No entanto, o Google diz que isso é feito por meio de tecnologias de difusão, utilizando uma imagem de ruído puro e refinando-a da melhor maneira possível. Ao entender a descrição de texto fornecida, o Imagen gerará uma imagem de 64 x 64 pixels, realizará duas melhorias e converterá a imagem em uma parte maior de 1024 x 1024 pixels.
Pesquisa do Google, Brain Team diz que Imagen se destacou em COCO (um conjunto de dados de detecção, segmentação e legendagem de objetos em grande escala) apesar de não ter sido treinado nele. A equipe informou que recebeu uma nova pontuação FID de última geração de 7.27.
O Google também comparou o desempenho do Imagen com outros modelos de texto para imagem, avaliando-os usando o “DrawBench”. Ele serve como referência para modelos de texto para imagem em que o Google testou o Imagen com outros métodos como VQ-GAN+CLIP, Modelos de difusão latente e DALL-E 2. Após testar sua composicionalidade, cardinalidade, relações espaciais, formato longo texto, palavras raras e solicitações desafiadoras, a equipe disse que “os avaliadores humanos preferem fortemente o Imagen a outros métodos, tanto no alinhamento da imagem-texto quanto na fidelidade da imagem”.
Apesar desses relatórios impressionantes da equipe de pesquisa, testar o Imagen por conta própria não será possível, pois não é acessível ao público. O Google tem motivos para isso, como desafios éticos, riscos potenciais de uso indevido, preconceitos sociais, limitações de grandes modelos de linguagem e risco de estereótipos e representações nocivos codificados. A equipe resume que com todos esses desafios, o Imagen ainda não é perfeito na hora de gerar imagens relacionadas a pessoas.
“O Imagen apresenta sérias limitações ao gerar imagens que retratam pessoas”, explica a equipe em uma postagem no blog. “Nossas avaliações humanas descobriram que o Imagen obtém taxas de preferência significativamente mais altas quando avaliadas em imagens que não retratam pessoas, indicando uma degradação na fidelidade da imagem. A avaliação preliminar também sugere que o Imagen codifica vários preconceitos e estereótipos sociais, incluindo um viés geral para gerar imagens de pessoas com tons de pele mais claros e uma tendência de imagens que retratam diferentes profissões se alinharem aos estereótipos de gênero ocidentais. Finalmente, mesmo quando focamos gerações longe das pessoas, nossa análise preliminar indica que o Imagen codifica uma série de vieses sociais e culturais ao gerar imagens de atividades, eventos e objetos. Nosso objetivo é progredir em vários desses desafios e limitações em aberto em trabalhos futuros.”