Czy Claude 3 jest naprawdę lepszy niż GPT-4? Benchmarking Promptbase mówi co innego
Bezpośrednie testy wykazały, że GPT-4 Turbo przewyższa Claude 3 we wszystkich kategoriach.
![]() 2 minuta. czytać
2 minuta. czytać
![]() Opublikowany
Opublikowany
Udostępnij ten artykuł

Ulepsz ten przewodnik
Przeczytaj naszą stronę z informacjami, aby dowiedzieć się, jak możesz pomóc MSPoweruser w utrzymaniu zespołu redakcyjnego Czytaj więcej
Kluczowe uwagi
- Niedawno firma Anthropic wypuściła na rynek Claude 3, reklamowany jako lepszy od GPT-4 i Google Gemini 1.0 Ultra.
- Zamieszczone wyniki testów porównawczych wskazują, że Claude 3 Opus wyróżnia się w różnych obszarach w porównaniu do swoich odpowiedników.
- Jednak dalsza analiza sugeruje, że GPT-4 Turbo przewyższa Claude 3 w bezpośrednich porównaniach, co sugeruje potencjalne błędy w raportowanych wynikach.

Anthropic właśnie uruchomił Claude 3 nie tak dawno temu model AI, który podobno był w stanie pokonać GPT-4 OpenAI i Google Gemini 1.0 Ultra. Występuje w trzech wariantach: Claude 3 Haiku, Sonnet i Opus, wszystkie do różnych zastosowań.
W swoich wstępne ogłoszeniefirma AI twierdzi, że Claude 3 jest nieco lepszy od tych dwóch niedawno wprowadzonych modeli.
Według opublikowanych wyników testów porównawczych Claude 3 Opus jest lepszy w wiedzy na poziomie licencjackim (MMLU), rozumowaniu na poziomie magisterskim (GPQA), matematyce w szkole podstawowej i rozwiązywaniu problemów matematycznych, matematyce wielojęzycznej, kodowaniu, rozumowaniu na podstawie tekstu i nie tylko niż GPT-4 i Gemini 1.0 Ultra i Pro.
Jednak nie oddaje to całkowicie prawdziwego obrazu sytuacji. Opublikowany wynik testu porównawczego w ogłoszeniu (szczególnie dla GPT-4) najwyraźniej został wzięty z GPT-4 w wersji z marca 2023 roku ubiegłego roku (podziękowania dla entuzjastów sztucznej inteligencji @TolgaBilge_ na X)
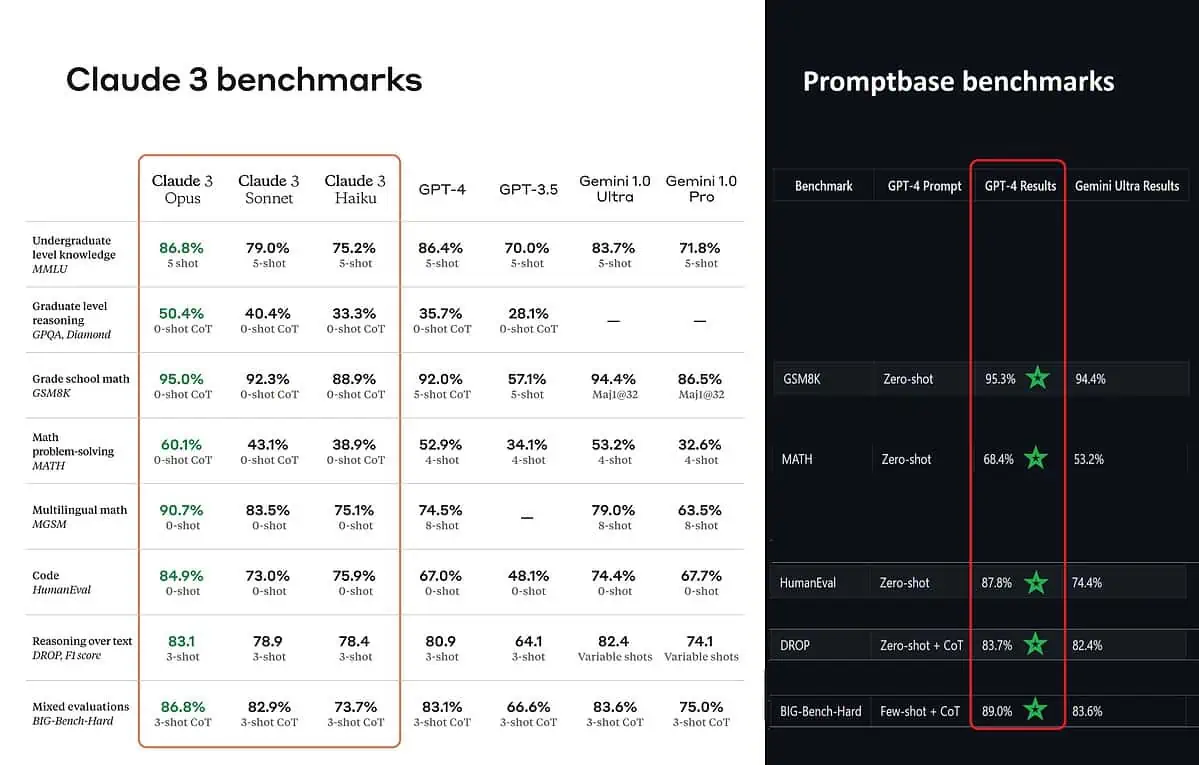
Narzędzie analizujące wydajność (analizator porównawczy) tzw Baza podpowiedzi pokazuje, że GPT-4 Turbo faktycznie pokonuje Claude 3 we wszystkich testach, w których mogli je bezpośrednio porównać. Testy te obejmują takie elementy, jak podstawowe umiejętności matematyczne (GSM8K i MATH), pisanie kodu (HumanEval), rozumowanie na podstawie tekstu (DROP) i szereg innych wyzwań.
Ogłaszając swoje wyniki, Anthropic również wspomina w przypisie że ich inżynierowie byli w stanie jeszcze bardziej poprawić wydajność GPT-4T, dostrajając go specjalnie na potrzeby testów. Sugeruje to, że raportowane wyniki mogą nie odzwierciedlać rzeczywistych możliwości modelu podstawowego.
Oooo.