Er Claude 3 virkelig bedre enn GPT-4? Promptbase sin benchmarking sier annerledes
Head-to-head tester viser at GPT-4 Turbo kanter ut Claude 3 i alle kategorier.
![]() 2 min. lese
2 min. lese
![]() Oppdatert på
Oppdatert på
Del denne artikkelen

Forbedre denne veiledningen
Les vår avsløringsside for å finne ut hvordan du kan hjelpe MSPoweruser opprettholde redaksjonen Les mer
Viktige merknader
- Anthropic lanserte nylig Claude 3, utpekt for å overgå GPT-4 og Google Gemini 1.0 Ultra.
- Postede benchmark-score indikerer at Claude 3 Opus utmerker seg på ulike områder sammenlignet med sine motparter.
- Videre analyse antyder imidlertid at GPT-4 Turbo overgår Claude 3 i direkte sammenligninger, noe som antyder potensielle skjevheter i rapporterte resultater.

Antropisk har nettopp lanserte Claude 3 for ikke så lenge siden, AI-modellen som sies å kunne slå OpenAIs GPT-4 og Google Gemini 1.0 Ultra. Den kommer med tre varianter: Claude 3 Haiku, Sonnet og Opus, alle for forskjellig bruk.
I sin innledende kunngjøring, sier AI-selskapet at Claude 3 er litt bedre enn disse to nylig lanserte modellene.
I følge de postede referanseresultatene er Claude 3 Opus bedre i kunnskap på lavere nivå (MMLU), resonnement på høyere nivå (GPQA), matematikk og matematikkproblemløsning på grunnskolen, flerspråklig matematikk, koding, resonnement over tekst og andre mer enn GPT-4 og Gemini 1.0 Ultra og Pro.
Imidlertid maler det ikke helt opp hele bildet sannferdig. Den postede benchmark-score på kunngjøringen (spesielt for GPT-4) ble tilsynelatende hentet fra GPT-4 på utgivelsesversjonen fra mars 2023 i fjor (kreditt til AI-entusiast @TolgaBilge_ på X)
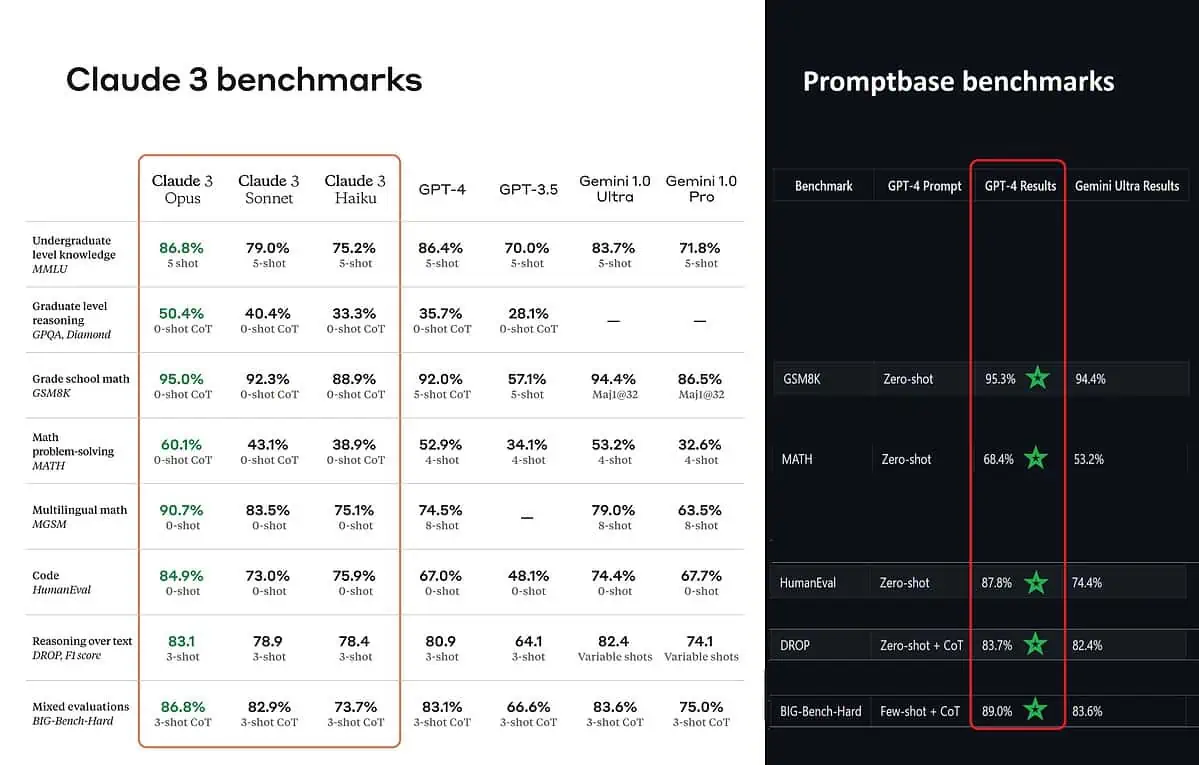
Et verktøy som analyserer ytelse (benchmark analysator) kalt ledetekstbase viser at GPT-4 Turbo faktisk slo Claude 3 i alle testene de direkte kunne sammenligne dem på. Disse testene dekker ting som grunnleggende matematiske ferdigheter (GSM8K & MATH), skrive kode (HumanEval), resonnering over tekst (DROP) og en blanding av andre utfordringer.
Mens de kunngjorde resultatene sine, Anthropic også nevner i en fotnote at ingeniørene deres var i stand til å forbedre GPT-4Ts ytelse ytterligere ved å finjustere den spesifikt for testene. Dette antyder at de rapporterte resultatene kanskje ikke gjenspeiler de sanne egenskapene til basismodellen.
Au.





Brukerforum
0 meldinger