Is Claude 3 echt beter dan GPT-4? De benchmarking van Promptbase zegt anders
Uit onderlinge tests blijkt dat GPT-4 Turbo in alle categorieën beter presteert dan Claude 3.
![]() 2 minuut. lezen
2 minuut. lezen
![]() Uitgegeven op
Uitgegeven op
deel dit artikel

Verbeter deze handleiding
Lees onze openbaarmakingspagina om erachter te komen hoe u MSPoweruser kunt helpen het redactieteam te ondersteunen Lees meer
Belangrijkste opmerkingen
- Anthropic heeft onlangs Claude 3 gelanceerd, waarvan wordt gezegd dat het beter presteert dan GPT-4 en Google Gemini 1.0 Ultra.
- Geposte benchmarkscores geven aan dat Claude 3 Opus op verschillende gebieden uitblinkt in vergelijking met zijn tegenhangers.
- Verdere analyse suggereert echter dat GPT-4 Turbo beter presteert dan Claude 3 in directe vergelijkingen, wat mogelijke vertekeningen in de gerapporteerde resultaten impliceert.

Antropisch heeft net lanceerde Claude 3 nog niet zo lang geleden, het AI-model waarvan wordt gezegd dat het OpenAI's GPT-4 en Google Gemini 1.0 Ultra kan verslaan. Het wordt geleverd met drie varianten: Claude 3 Haiku, Sonnet en Opus, allemaal voor verschillende toepassingen.
In de eerste aankondigingzegt het AI-bedrijf dat Claude 3 iets superieur is aan deze twee onlangs gelanceerde modellen.
Volgens de geposte benchmarkscores is Claude 3 Opus beter in kennis op bachelorniveau (MMLU), redeneren op graduate niveau (GPQA), wiskunde op de basisschool en het oplossen van wiskundeproblemen, meertalige wiskunde, coderen, redeneren over tekst en meer. dan GPT-4 en Gemini 1.0 Ultra en Pro.
Dat geeft echter niet het hele beeld volledig waarheidsgetrouw weer. De gepubliceerde benchmarkscore op de aankondiging (vooral voor GPT-4) is blijkbaar overgenomen van GPT-4 op de releaseversie van maart 2023 vorig jaar (credits aan AI-liefhebber @TolgaBilge_ op X)
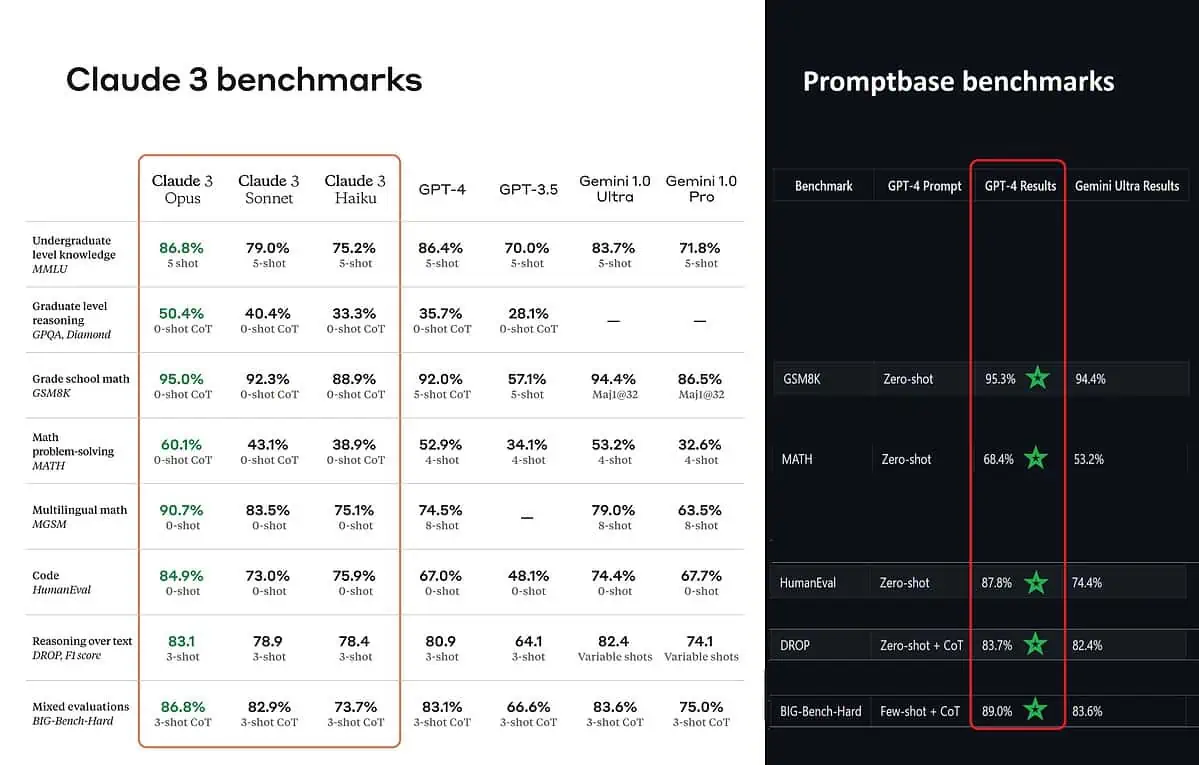
Een tool die de prestaties analyseert (benchmarkanalysator), genaamd Promptbasis laat zien dat GPT-4 Turbo daadwerkelijk Claude 3 verslaat in alle tests waarop ze ze rechtstreeks konden vergelijken. Deze tests omvatten zaken als elementaire wiskundige vaardigheden (GSM8K & MATH), code schrijven (HumanEval), redeneren over tekst (DROP) en een mix van andere uitdagingen.
Terwijl Anthropic hun resultaten bekendmaakte, ook vermeldt in een voetnoot dat hun ingenieurs de prestaties van de GPT-4T verder konden verbeteren door deze specifiek voor de tests te verfijnen. Dit suggereert dat de gerapporteerde resultaten mogelijk niet de werkelijke mogelijkheden van het basismodel weerspiegelen.
Ouch.