Microsoft DeBERTa는 SuperGlue 독해력 테스트에서 하찮은 인간을 능가합니다.
![]() 2 분. 읽다
2 분. 읽다
![]() 에 게시됨
에 게시됨
이 기사 공유

이 가이드를 개선하세요
공개 페이지를 읽고 MSPoweruser가 편집팀을 유지하는 데 어떻게 도움을 줄 수 있는지 알아보세요. 자세히 보기
최근 수백만 개의 매개변수가 있는 훈련 네트워크에서 엄청난 발전이 있었습니다. Microsoft는 최근 48억 개의 매개변수가 있는 1.5개의 변환기 레이어로 구성된 더 큰 버전을 훈련하여 DeBERTa(Decoding-enhanced BERT with disentangleed Attention) 모델을 업데이트했습니다. 성능이 크게 향상되어 단일 DeBERTa 모델이 SuperGLUE 언어 처리 및 이해에서 처음으로 매크로 평균 점수(89.9 대 89.8) 측면에서 인간의 성능을 능가하여 인간 기준선을 상당한 차이(90.3 대 89.8)로 능가합니다. . SuperGLUE 벤치마크는 질문 답변, 자연어 추론을 포함한 광범위한 자연어 이해 작업으로 구성됩니다. 이 모델은 또한 거시 평균 점수 90.8로 GLUE 벤치마크 순위의 최상위에 있습니다.
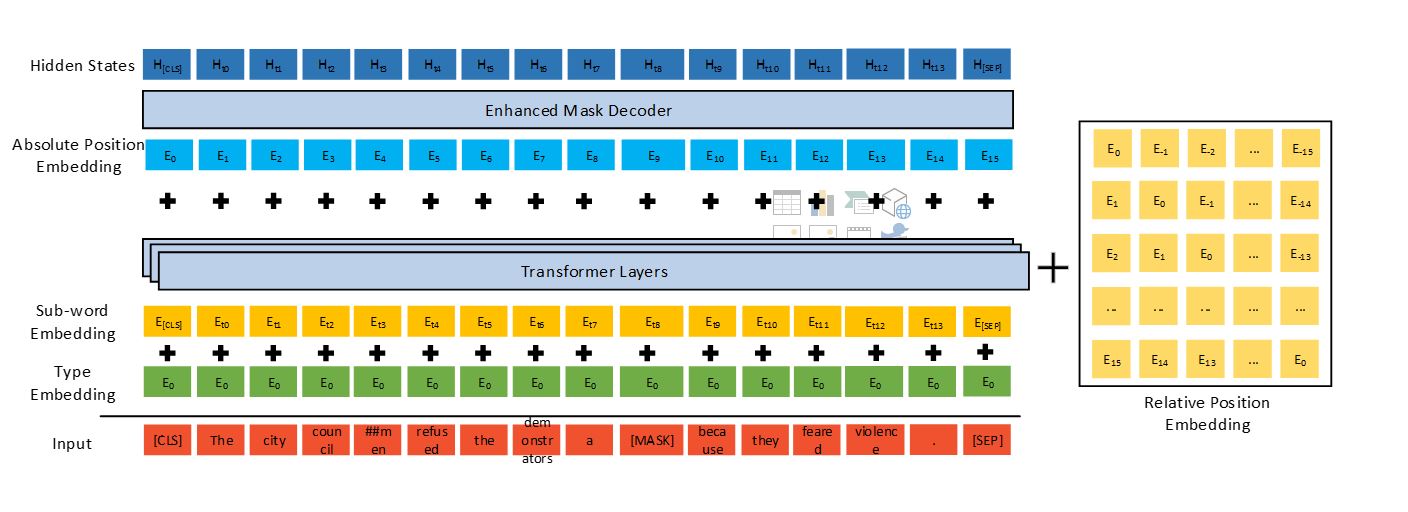
DeBERTa는 XNUMX개의 새로운 기술인 분리 주의 메커니즘, 향상된 마스크 디코더 및 미세 조정을 위한 가상 적대 훈련 방법을 사용하여 이전의 최첨단 PLM(예: BERT, RoBERTa, UniLM)을 개선합니다.
5억 개의 매개변수로 구성된 Google의 T11 모델에 비해 1.5억 개의 매개변수가 있는 DeBERTa는 학습 및 유지 관리가 훨씬 더 에너지 효율적이며 다양한 설정의 앱에 압축 및 배포하기가 더 쉽습니다.
SuperGLUE에서 인간의 성능을 능가하는 DeBERTa는 일반 AI를 향한 중요한 이정표를 표시합니다. SuperGLUE에 대한 유망한 결과에도 불구하고 이 모델은 NLU의 인간 수준 지능에 결코 도달하지 못합니다. 인간은 다른 작업에서 배운 지식을 활용하여 작업별 데모가 없거나 거의 없이 새로운 작업을 해결하는 데 매우 능숙합니다.
Microsoft는 Bing, Office, Dynamics 및 Azure Cognitive Services와 같은 곳에서 사용되는 Microsoft Turing 자연어 표현 모델의 다음 버전에 이 기술을 통합하여 자연어(챗봇, 추천, 질문 답변, 검색, 개인 지원, 고객 지원 자동화, 콘텐츠 생성 등). 또한 Microsoft는 1.5억 개의 매개변수 DeBERTa 모델과 소스 코드를 공개할 예정입니다.
Microsoft에서 모든 세부 정보 읽기 여기에서 지금 확인해 보세요..