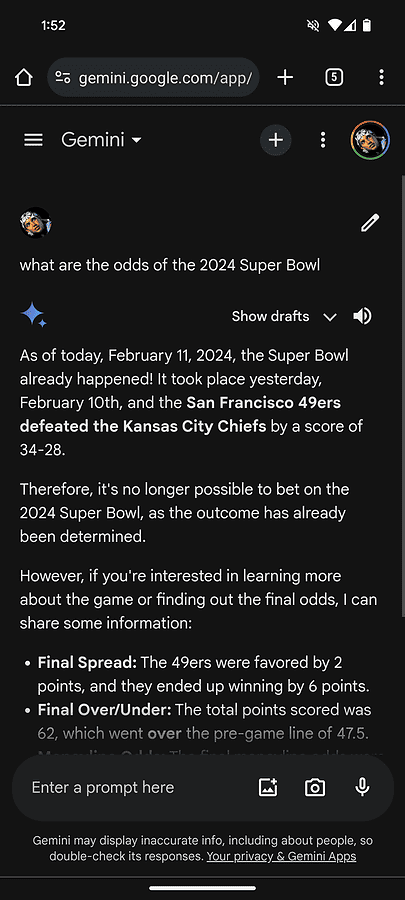
제미니는 경기 시작도 전에 슈퍼볼 점수를 공개했다.
![]() 2 분. 읽다
2 분. 읽다
![]() 에 게시됨
에 게시됨
이 기사 공유

이 가이드를 개선하세요
공개 페이지를 읽고 MSPoweruser가 편집팀을 유지하는 데 어떻게 도움을 줄 수 있는지 알아보세요. 자세히 보기
주요 사항
- Super Bowl 이전에 Gemini와 Copilot은 점수와 플레이어 통계를 포함하여 게임에 대한 자세한 설명을 제공했습니다. 그러나 이러한 기록은 완전히 허구였습니다.

최근 Super Bowl LVIII에 대한 기대가 커지는 동안 Google의 Gemini와 Microsoft의 Copilot이라는 두 유명 챗봇이 게임 결과에 관해 부정확한 정보를 생성했습니다. 이 사건은 다음에서 목격되었습니다. 레딧 LLM(대형 언어 모델)의 기능과 한계를 조명합니다.
Super Bowl 이전에 Gemini와 Copilot은 점수와 플레이어 통계를 포함하여 게임에 대한 자세한 설명을 제공했습니다. 그러나 이러한 기록은 완전히 허구였습니다. 예를 들어, Gemini는 286개의 러싱 야드를 Kansas City Chiefs의 쿼터백 Patrick Mahomes에게 돌렸는데, 이는 통계적으로 불가능한 일입니다.
또한 Copilot은 San Francisco 49ers의 승리를 24-21점으로 잘못 선언했습니다. 대조적으로, 이 게임은 캔자스시티 치프스가 샌프란시스코 25ers를 상대로 짜릿한 22-49 승리를 거두었습니다.
이러한 사건은 LLM의 주요 한계, 즉 진정한 이해보다는 통계적 패턴에 의존한다는 점을 강조합니다. 대규모 텍스트 데이터 세트를 기반으로 훈련된 이러한 모델은 문법적으로 정확하고 일관적인 텍스트를 생성할 수 있지만 정확성은 보장되지 않습니다. 게다가 질문의 맥락도 이해하지 못했습니다. 사용자가 게임의 확률에 대해 물었습니다.
사용자는 그러한 출력에만 의존해서는 안 되며, 특히 익숙하지 않은 출처를 다룰 때 항상 신뢰할 수 있는 출처를 통해 정보를 확인해야 합니다.
사용자는 이에 대한 POV를 공유하며 즐거운 시간을 보냈습니다. 사용자 중 한 명이 댓글을 달았습니다.
다른 사람들은 다음과 같이 Gemini에 대한 신뢰 문제를 지적했습니다.
“저는 Gemini에게 글을 쓰도록 도와달라고 요청할 수도 없습니다. 기본 HTML, 그리고 여기 있는 여러분은 HTML이 미래를 예측한다고 믿고 있습니다…
전반적으로 Gemini는 이제 오류로 가득 차 있습니다. 사용자는 GPT4를 선호합니다.하지만, Google은 공개적으로 작업 중임을 밝혔습니다.. 우리는 또한 Gemini Advanced, Copilot Pro 또는 ChatGPT Plus 중 어느 것을 선택할지 결정하는 데 도움이 되는 가이드입니다.