Il generatore da testo a immagine di Google Imagen produce immagini con un "grado di fotorealismo senza precedenti"
![]() 3 minuto. leggere
3 minuto. leggere
![]() Edizione del
Edizione del
Condividi questo articolo

Migliora questa guida
Leggi la nostra pagina informativa per scoprire come puoi aiutare MSPoweruser a sostenere il team editoriale Per saperne di più
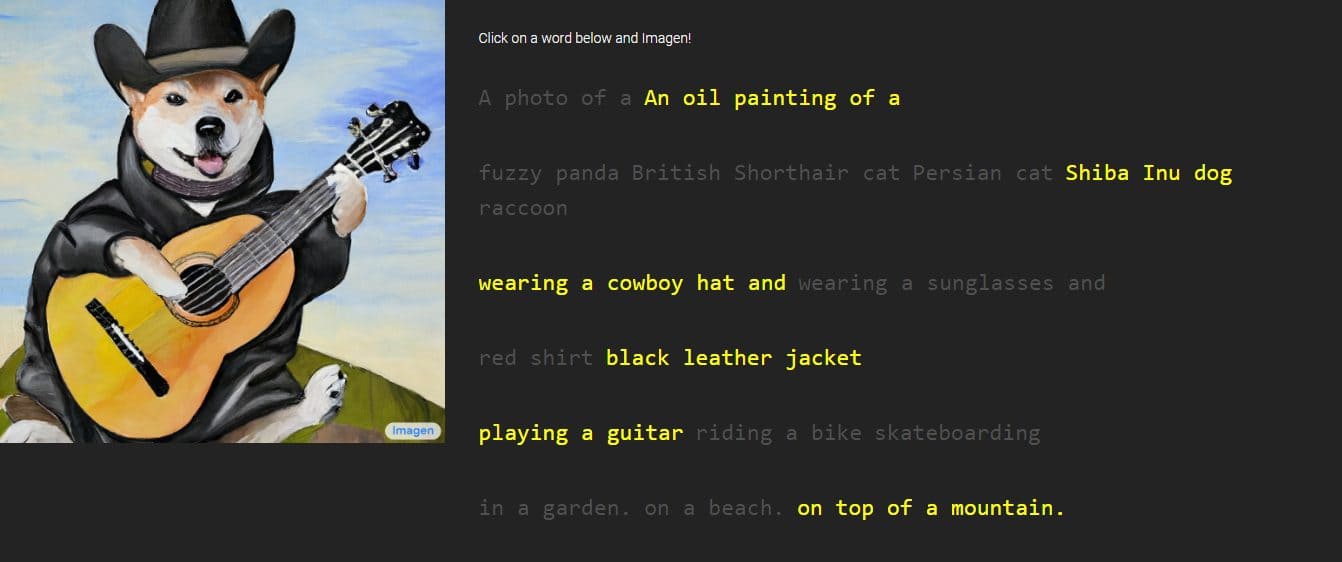
Google ha svelato una nuova creazione chiamata “Immagine”, un generatore di testo in immagine attraverso le descrizioni che una persona fornirà. L'azienda afferma di superare le prestazioni di DALL-E 2, un altro generatore di immagini AI. Ha presentato alcuni campioni, che mostrano innegabilmente dettagli squisiti, ma Imagen non è attualmente disponibile al pubblico.
Il nuovo modello di diffusione da testo a immagine è descritto per avere "un grado di fotorealismo senza precedenti e un profondo livello di comprensione del linguaggio". Comprende il testo attraverso grandi modelli di linguaggio di trasformazione e si dice che faccia affidamento su modelli di diffusione per eseguire la generazione di immagini ad alta fedeltà.

Google ha fornito immagini ed esempi del lavoro di Imagen, con stili che variano dai disegni ai dipinti a olio e CGI. Sono accompagnati dalle parole e dalle frasi usate per generarli. Ad esempio, un campione recita "un frutto del drago che indossa una cintura da karate nella neve", mentre l'altro ha la descrizione "un piccolo cactus con un cappello di paglia e occhiali da sole al neon nel deserto del Sahara".
Le immagini generate sembrano incredibilmente reali come se fossero state create da una persona reale. Tuttavia, Google afferma che ciò avviene attraverso tecnologie di diffusione utilizzando un'immagine di puro rumore e perfezionandola nel miglior modo possibile. Comprendendo la descrizione del testo fornita, Imagen genererà un'immagine di 64 x 64 pixel, eseguirà due miglioramenti e convertirà l'immagine in un pezzo più grande di 1024 x 1024 pixel.
Google Research, Brain Team afferma che Imagen eccelleva COCO (un set di dati di rilevamento, segmentazione e sottotitoli di oggetti su larga scala) nonostante non sia stato addestrato su di esso. Il team ha riferito di aver ricevuto un nuovo punteggio FID all'avanguardia di 7.27.
Google ha anche confrontato le prestazioni di Imagen con altri modelli da testo a immagine valutandoli utilizzando "DrawBench". Serve come punto di riferimento per i modelli text-to-image in cui Google ha testato Imagen con altri metodi come VQ-GAN+CLIP, Latent Diffusion Models e DALL-E 2. Dopo aver testato la loro composizionalità, cardinalità, relazioni spaziali, formato lungo testo, parole rare e suggerimenti stimolanti, il team ha affermato che "i valutatori umani preferiscono fortemente Imagen rispetto ad altri metodi, sia nell'allineamento immagine-testo che nella fedeltà dell'immagine".
Nonostante questi impressionanti rapporti del team di ricerca, testare Imagen da soli non sarà possibile in quanto non è accessibile al pubblico. Google ha ragioni per questo, come sfide etiche, potenziali rischi di uso improprio, pregiudizi sociali, limitazioni di modelli linguistici di grandi dimensioni e rischio di stereotipi e rappresentazioni dannose codificate. Il team riassume che con tutte queste sfide, Imagen non è ancora perfetto quando si tratta di generare immagini relative alle persone.
"Imagen mostra seri limiti durante la generazione di immagini che ritraggono persone", spiega il team in un post sul blog. “Le nostre valutazioni umane hanno rilevato che Imagen ottiene tassi di preferenza significativamente più elevati se valutato su immagini che non ritraggono persone, indicando un degrado nella fedeltà dell'immagine. La valutazione preliminare suggerisce anche che Imagen codifichi diversi pregiudizi e stereotipi sociali, inclusa una tendenza generale verso la generazione di immagini di persone con carnagioni più chiare e una tendenza per le immagini che ritraggono professioni diverse ad allinearsi con gli stereotipi di genere occidentali. Infine, anche quando concentriamo le generazioni lontano dalle persone, la nostra analisi preliminare indica che Imagen codifica una serie di pregiudizi sociali e culturali quando genera immagini di attività, eventi e oggetti. Miriamo a fare progressi su molte di queste sfide e limitazioni aperte nel lavoro futuro".