Je li Claude 3 stvarno bolji od GPT-4? Promptbaseov benchmarking kaže drugačije
Direktni testovi pokazuju da GPT-4 Turbo nadmašuje Claude 3 u svim kategorijama.
![]() 2 min. čitati
2 min. čitati
![]() Objavljeno na
Objavljeno na
Podijelite ovaj članak

Poboljšajte ovaj vodič
Pročitajte našu stranicu za otkrivanje kako biste saznali kako možete pomoći MSPoweruseru da održi urednički tim Čitaj više
Ključne napomene
- Anthropic je nedavno lansirao Claude 3, za koji se reklamira da će nadmašiti GPT-4 i Google Gemini 1.0 Ultra.
- Objavljeni referentni rezultati pokazuju da se Claude 3 Opus ističe u raznim područjima u usporedbi sa svojim kolegama.
- Međutim, daljnja analiza sugerira da GPT-4 Turbo nadmašuje Claude 3 u izravnim usporedbama, što ukazuje na potencijalne pristranosti u prijavljenim rezultatima.

Anthropic je upravo lansirao Claude 3 ne tako davno, njegov AI model za koji se kaže da može pobijediti OpenAI GPT-4 i Google Gemini 1.0 Ultra. Dolazi s tri varijante: Claude 3 Haiku, Sonnet i Opus, sve za različite namjene.
U svom početna najava, tvrtka AI kaže da je Claude 3 malo bolji od ova dva nedavno lansirana modela.
Prema objavljenim referentnim rezultatima, Claude 3 Opus je bolji u znanju na dodiplomskoj razini (MMLU), zaključivanju na diplomskoj razini (GPQA), matematici u osnovnoj školi i rješavanju matematičkih problema, višejezičnoj matematici, kodiranju, rasuđivanju preko teksta i još mnogo toga nego GPT-4 i Gemini 1.0 Ultra i Pro.
Međutim, to ne prikazuje u potpunosti istinitu cijelu sliku. Objavljeni referentni rezultat u najavi (posebice za GPT-4) očito je preuzet iz GPT-4 na verziji izdanja iz ožujka 2023. prošle godine (zasluge AI entuzijastu @TolgaBilge_ na X)
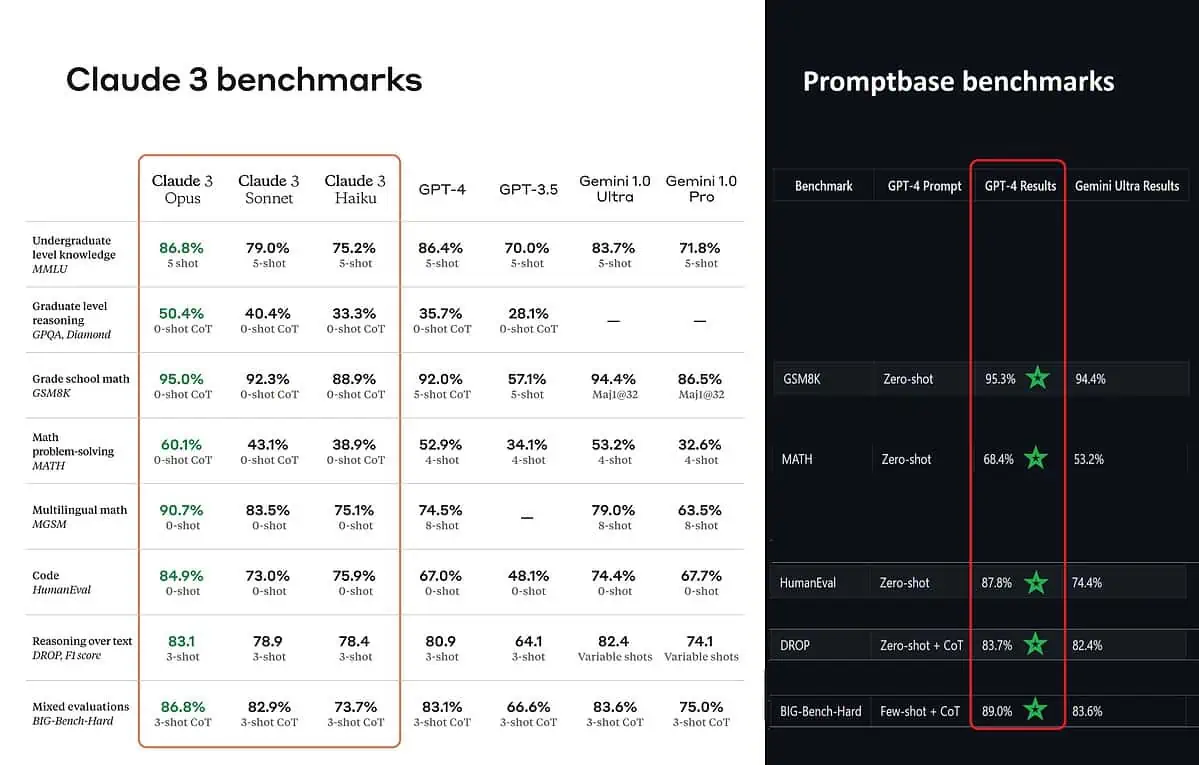
Alat koji analizira performanse (benchmark analizator) tzv Promptbase pokazuje da GPT-4 Turbo zapravo pobjeđuje Claude 3 u svim testovima na kojima su ih mogli izravno usporediti. Ovi testovi pokrivaju stvari kao što su osnovne matematičke vještine (GSM8K & MATH), pisanje koda (HumanEval), razmišljanje o tekstu (DROP) i mješavinu drugih izazova.
Objavljujući rezultate, Anthropic također spominje u bilješci da su njihovi inženjeri uspjeli dodatno poboljšati performanse GPT-4T finim podešavanjem posebno za testove. Ovo sugerira da prijavljeni rezultati možda ne odražavaju stvarne mogućnosti osnovnog modela.
Ouch.