Claude 3 est-il vraiment meilleur que GPT-4 ? L'analyse comparative de Promptbase dit le contraire
Les tests face-à-face montrent que GPT-4 Turbo devance Claude 3 dans toutes les catégories.
![]() 2 minute. lis
2 minute. lis
![]() Mis à jour le
Mis à jour le
Partagez cet article

Améliorer ce guide
Lisez notre page de divulgation pour savoir comment vous pouvez aider MSPoweruser à soutenir l'équipe éditoriale Plus d'informations
Notes clés
- Anthropic a récemment lancé Claude 3, censé surpasser GPT-4 et Google Gemini 1.0 Ultra.
- Les scores de référence affichés indiquent que Claude 3 Opus excelle dans divers domaines par rapport à ses homologues.
- Cependant, une analyse plus approfondie suggère que GPT-4 Turbo surpasse Claude 3 en comparaison directe, ce qui implique des biais potentiels dans les résultats rapportés.

Anthropic vient de a lancé Claude 3 il n'y a pas si longtemps, son modèle d'IA serait capable de battre le GPT-4 d'OpenAI et Google Gemini 1.0 Ultra. Il se décline en trois variantes : Claude 3 Haiku, Sonnet et Opus, toutes pour des usages différents.
Dans son annonce initiale, la société d'IA affirme que Claude 3 est légèrement supérieur à ces deux modèles récemment lancés.
Selon les scores de référence affichés, Claude 3 Opus est meilleur en connaissances de premier cycle (MMLU), en raisonnement de niveau supérieur (GPQA), en mathématiques à l'école primaire et en résolution de problèmes mathématiques, en mathématiques multilingues, en codage, en raisonnement sur texte et bien d'autres. que GPT-4 et Gemini 1.0 Ultra et Pro.
Cependant, cela ne donne pas une image fidèle de l’ensemble de la situation. Le score de référence affiché lors de l'annonce (en particulier pour GPT-4) a apparemment été tiré de GPT-4 sur la version de mars 2023 de l'année dernière (crédits aux passionnés d'IA @TolgaBilge_ sur X)
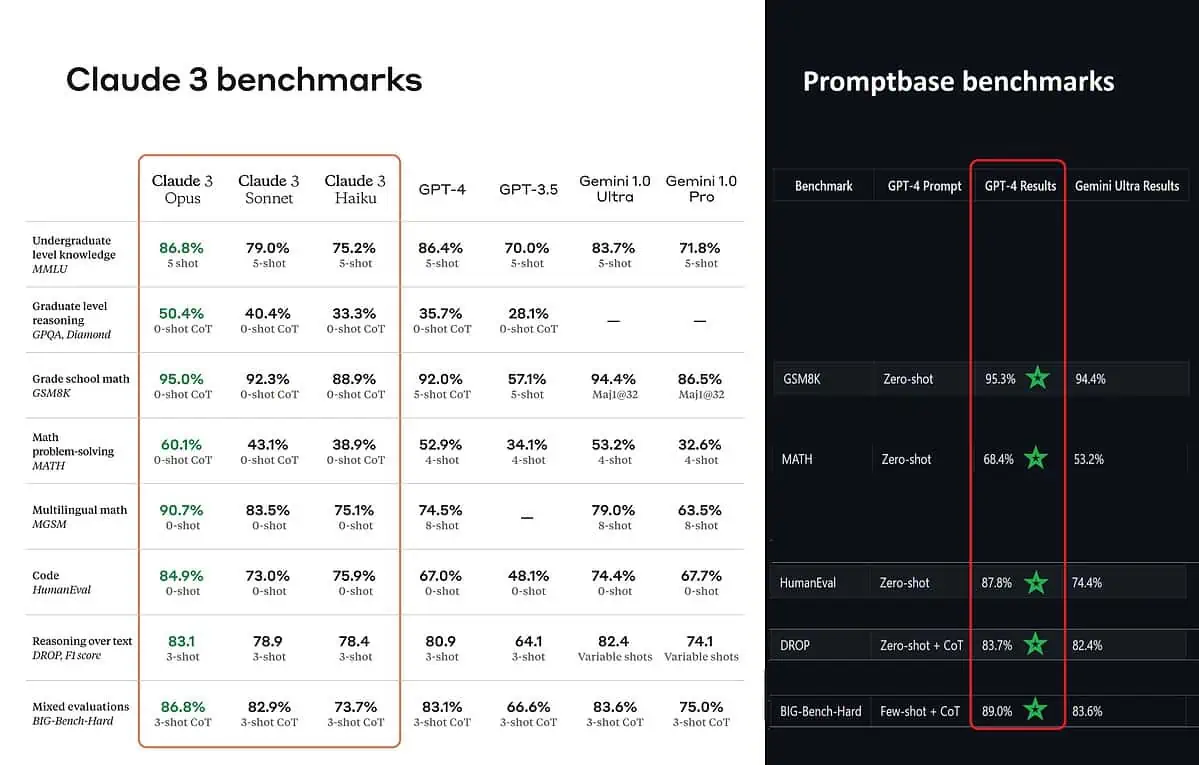
Un outil d'analyse des performances (analyseur de référence) appelé Base d'invite montre que GPT-4 Turbo bat effectivement Claude 3 dans tous les tests sur lesquels ils ont pu les comparer directement. Ces tests couvrent des éléments tels que les compétences mathématiques de base (GSM8K & MATH), l'écriture de code (HumanEval), le raisonnement sur texte (DROP) et un mélange d'autres défis.
En annonçant ses résultats, Anthropic a également mentionne dans une note de bas de page que leurs ingénieurs ont pu améliorer encore les performances du GPT-4T en le peaufinant spécifiquement pour les tests. Cela suggère que les résultats rapportés pourraient ne pas refléter les véritables capacités du modèle de base.
Aie.





Forum des utilisateurs
Messages 0