Snowflake Arctic ist stolz darauf, das „beste LLM für Unternehmens-KI“ zu sein. Das ist eine ziemlich große Behauptung
Sie können Snowflake jetzt auf HuggingFace ausprobieren
![]() 2 Minute. lesen
2 Minute. lesen
![]() Veröffentlicht am
Veröffentlicht am
Teile diesen Artikel

Verbessern Sie diesen Leitfaden
Lesen Sie unsere Offenlegungsseite, um herauszufinden, wie Sie MSPoweruser dabei helfen können, das Redaktionsteam zu unterstützen Mehr Infos
Wichtige Hinweise
- Snowflake stellt Arctic vor und behauptet, dass es mit Llama 3 70B mit geringeren Kosten konkurriert.
- Arctic zeichnet sich durch Unternehmensaufgaben wie Codierung und SQL-Generierung aus.
- Mithilfe eines Dense-MoE-Hybrids optimiert Arctic die Effizienz für verschiedene Chargengrößen.

Snowflake, ein Cloud-Computing-Riese, der ursprünglich von ehemaligen Oracle-Wissenschaftlern gegründet wurde, fordert nun die großen Player im KI-Krieg heraus. Das Unternehmen wurde gegründet Schneeflocken-Arktis, sein neuestes „bestes LLM für Unternehmens-KI“, und behauptete, es sei besser als auf Augenhöhe mit Llama 3 70B und besser als dessen 8B-Variante.
In seiner Ankündigung behauptet Snowflake, dass das Arctic-Modell die Leistung von Llama 3 70B erreicht, jedoch geringere Rechenanforderungen und Kosten aufweist. Es wird als ideal für Enterprise-Intelligence-Aufgaben in Bereichen und Benchmarks wie Codierung (HumanEval+ und MBPP+), SQL-Generierung (Spider) und Befehlsfolge (IFEval) angepriesen.
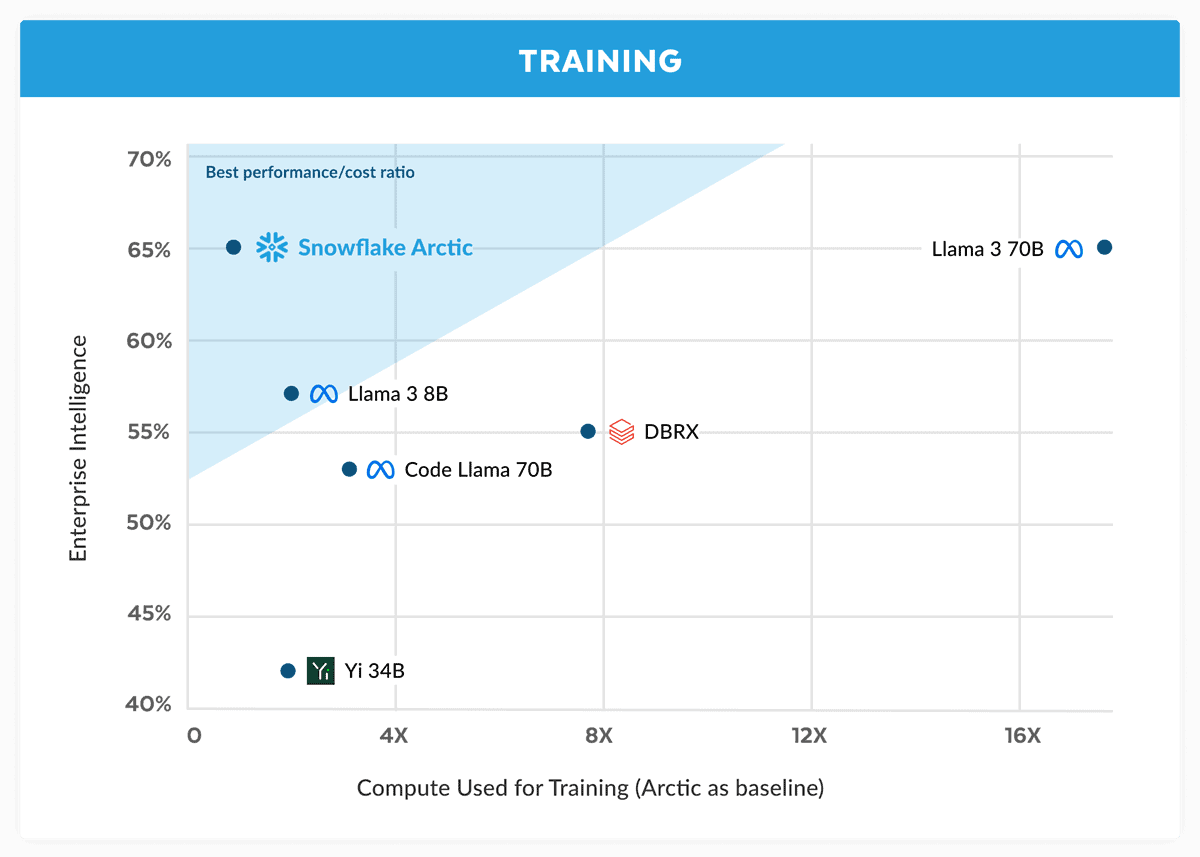
Das ist eine große Behauptung, vor allem wenn man das bedenkt Lama 3 70B hat sich in wichtigen Tests gut gegen andere große Modelle wie GPT-4 Turbo und Claude 3 Opus geschlagen. Berichten zufolge schneidet Metas kommendes Modell in Benchmarks wie MMLU (für das Verstehen von Fächern), GPQA (Biologie, Physik und Chemie) und HumanEval (Kodierung) gut ab.
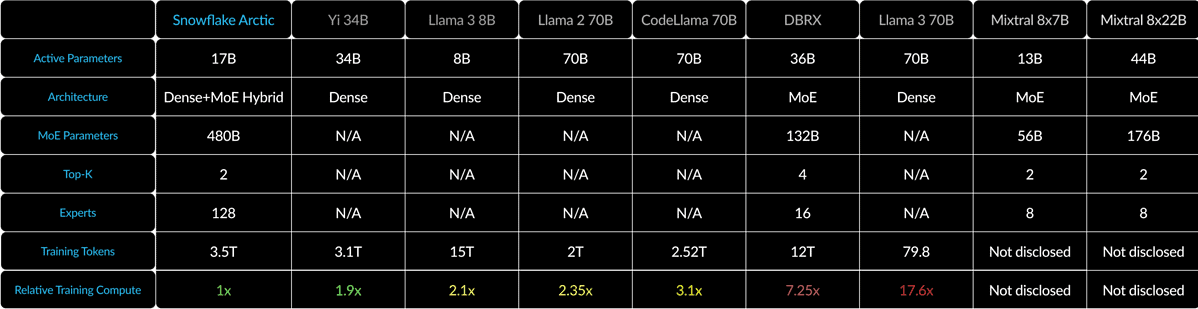
Snowflake Arctic mischt einen 10-B-Dichttransformator mit einem 128×3.66-B-MoE-MLP unter Verwendung eines Dense-MoE-Hybrids. Das sind insgesamt 480B Parameter, aber nur 17B werden aktiv genutzt und mit Top-2-Gating ausgewählt.
Bei kleinen Losgrößen wie 1 reduziert Arctic die Speicherlesevorgänge im Vergleich zu Code-Llama 4B um bis zu 70x und bis zu 2.5x weniger als Mixtral 8x22B. Da die Batch-Größen jedoch deutlich ansteigen, wird Arctic an die Rechenleistung gebunden. Der Rechenaufwand ist viermal geringer als bei CodeLlama 4B und Llama 70 3B.
Sie können Snowflake Arctic ausprobieren Umarmendes Gesicht. Das Unternehmen verspricht außerdem, dass das Modell bald auch in anderen Modellgärten wie AWS, Microsoft Azure, Perplexity und anderen verfügbar sein wird.




Benutzerforum
0 Nachrichten