Je Claude 3 opravdu lepší než GPT-4? Benchmarking Promptbase říká něco jiného
Vzájemné testy ukazují, že GPT-4 Turbo překonává Claude 3 ve všech kategoriích.
![]() 2 min. číst
2 min. číst
![]() Aktualizováno dne
Aktualizováno dne
Sdílejte tento článek

Vylepšete tuto příručku
Přečtěte si naši informační stránku a zjistěte, jak můžete pomoci MSPoweruser udržet redakční tým Více informací
Klíčové poznámky
- Společnost Anthropic nedávno uvedla na trh Claude 3, který má překonat GPT-4 a Google Gemini 1.0 Ultra.
- Zveřejněné výsledky benchmarků ukazují, že Claude 3 Opus vyniká v různých oblastech ve srovnání se svými protějšky.
- Další analýza však naznačuje, že GPT-4 Turbo překonává Claude 3 v přímých srovnáních, což naznačuje potenciální zkreslení v hlášených výsledcích.

Antropický má právě spustil Claude 3 není to tak dávno, jeho model AI, o kterém se říká, že je schopen porazit OpenAI GPT-4 a Google Gemini 1.0 Ultra. Dodává se se třemi variantami: Claude 3 Haiku, Sonnet a Opus, všechny pro různá použití.
V jeho počáteční oznámeníAI společnost říká, že Claude 3 je o něco lepší než tyto dva nedávno uvedené modely.
Podle zveřejněných srovnávacích skóre je Claude 3 Opus lepší ve znalostech na vysokoškolské úrovni (MMLU), uvažování na úrovni absolventa (GPQA), v matematice na základní škole a řešení matematických problémů, ve vícejazyčné matematice, kódování, uvažování nad textem a dalších dalších. než GPT-4 a Gemini 1.0 Ultra a Pro.
To však nevykresluje celý obraz pravdivě. Zveřejněné benchmarkové skóre při oznámení (zejména pro GPT-4) bylo zjevně převzato z GPT-4 ve verzi z března 2023 minulého roku (poděkování nadšencům AI @TolgaBilge_ na X)
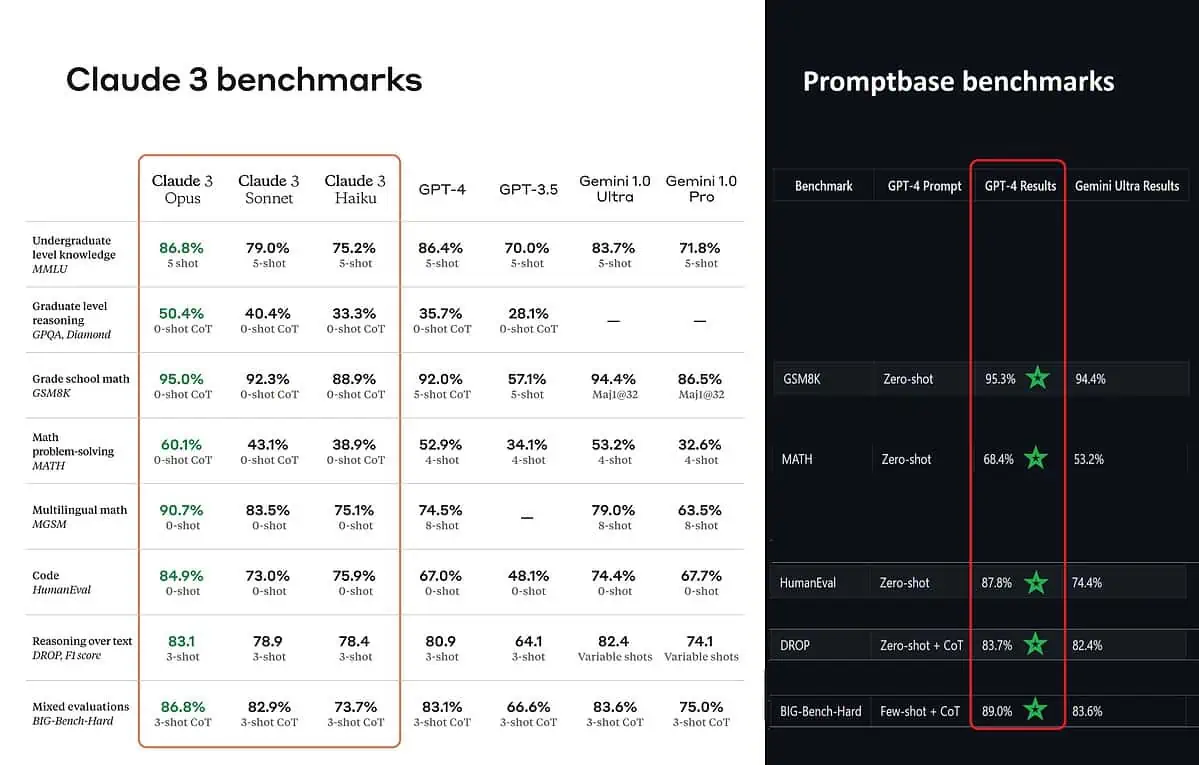
Nástroj, který analyzuje výkon (benchmark analyzátor), tzv Promptbase ukazuje, že GPT-4 Turbo skutečně poráží Claude 3 ve všech testech, se kterými je mohli přímo porovnat. Tyto testy pokrývají věci jako základní matematické dovednosti (GSM8K & MATH), psaní kódu (HumanEval), uvažování nad textem (DROP) a směs dalších výzev.
Při vyhlašování svých výsledků také Anthropic zmiňuje v poznámce pod čarou že jejich inženýři byli schopni dále zlepšit výkon GPT-4T jeho jemným doladěním speciálně pro testy. To naznačuje, že uvedené výsledky nemusí odrážet skutečné možnosti základního modelu.
Ouch.





Uživatelské fórum
0 zprávy